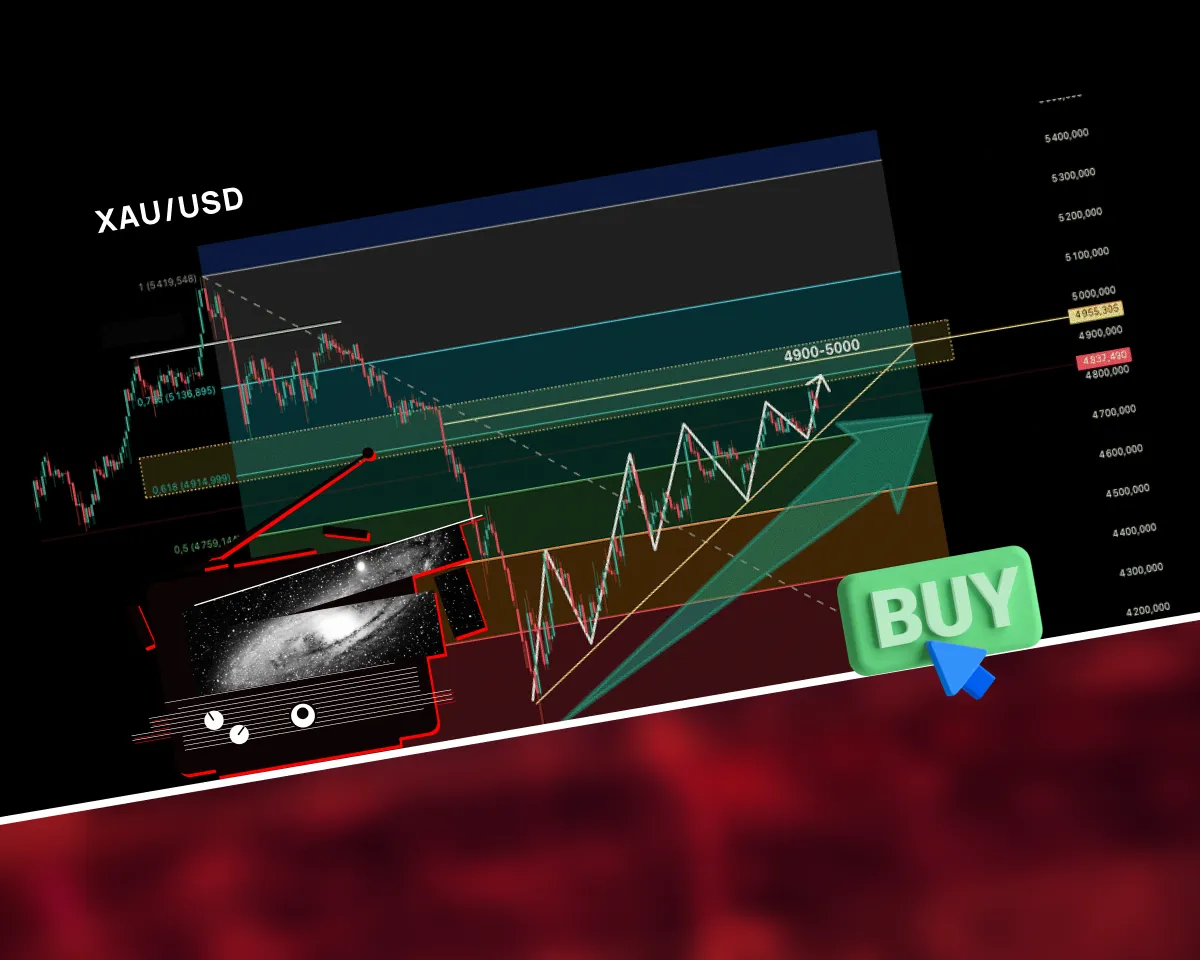
Bitwarden CLI hack, arrest of illicit debt collectors in Kyiv, and other cybersecurity newsThe week's key cybersecurity stories: AI-fuelled DPRK heists, Bitwarden CLI breach, spyware spread.
We have compiled the week's most important cybersecurity news.