




A group of researchers employed the weekly puzzle segment by NPR host Will Shortz to assess the “reasoning” skills of artificial intelligence models.
Experts from several American colleges and universities, supported by the startup Cursor, developed a universal test for AI models using puzzles from the Sunday Puzzle episodes. According to the team, the study revealed intriguing details, including the fact that chatbots sometimes “give up” and consciously provide incorrect answers.
Sunday Puzzle is a weekly radio quiz where listeners are asked questions about logic and syntax. Solving them does not require special theoretical knowledge but demands critical thinking and reasoning skills.
One of the study’s co-authors, Arjun Guha, explained to TechCrunch the advantage of the “puzzle” method, noting that it does not test for esoteric knowledge, and the task formulations make it difficult for AI models to rely on “mechanical memory.”
“These puzzles are challenging because it’s very hard to make meaningful progress until you solve them — that’s when the final answer immediately comes together. It requires a combination of intuition and the process of elimination,” he explained.
However, Guha noted the method’s imperfections — the Sunday Puzzle is geared towards an English-speaking audience, and the tests are publicly available, allowing AI to “cheat.” Researchers plan to expand the benchmark with new puzzles, which currently consists of approximately 600 tasks.
In the conducted tests, o1 and DeepSeek R1 significantly outperformed other models in their “reasoning” ability. The leading neural networks meticulously checked themselves before answering, but the process took them much longer than usual.


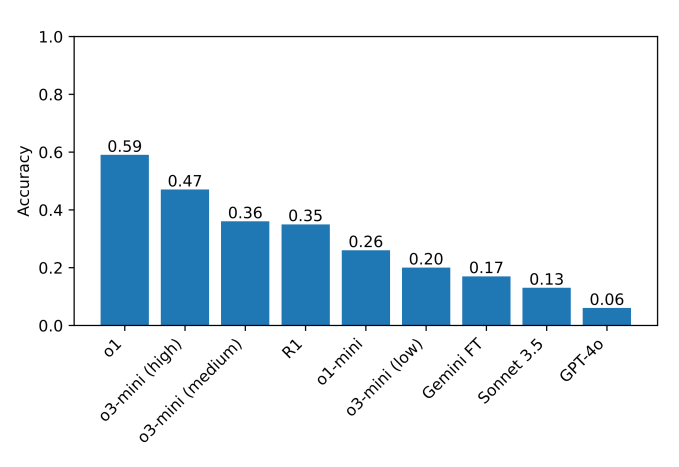
However, AI accuracy does not exceed 60%. Some models outright refused to solve the puzzles. When the DeepSeek neural network could not find the correct answer, it would write during the reasoning process: “I give up,” and then provide an incorrect answer, seemingly chosen at random.
Other models repeatedly tried to correct previous mistakes but still failed. AIs would get “stuck in thought,” generate nonsense, and sometimes give correct answers only to later reject them.



“In complex tasks, R1 from DeepSeek literally says it’s ‘frustrated.’ It’s amusing to see the model mimic what a human might say. It remains to be seen how ‘frustration’ in reasoning might affect the quality of the model’s results,” Guha emphasized.
Earlier, a researcher tested seven popular chatbots in a chess tournament. None of the neural networks managed to fully handle the game.