


DeepSeek jolts markets: why a Chinese AI proved 30 times more efficient than GPT-4
In late January, the little-known Chinese startup DeepSeek found itself in the global spotlight. A modest $5.6m investment in developing a new model turned into a blow to markets — US tech giants collectively lost almost $1 trillion in market value.
The arrival of a low-cost alternative to ChatGPT, touted as a “Silicon Valley killer”, set the industry abuzz. ForkLog explains where DeepSeek came from, how it succeeded and what may lie ahead for the global market in language models.
DeepSeek’s rise
DeepSeek struck out on its own in May 2023 in Hangzhou, the capital of Zhejiang province. The city is China’s biggest e-commerce hub, home to the headquarters of giants such as Alibaba Group, Geely, Hikvision and Ant Group.
Behind the project stands Liang Wenfeng — an entrepreneur and co-founder of the hedge fund High-Flyer, managing $8bn in assets. Founded in 2015, the firm long showed an interest in machine learning, investing heavily in its own computing infrastructure as well as AI research. DeepSeek emerged from that structure.
In 2020 High-Flyer unveiled the Fire-Flyer I supercomputer costing 200m yuan ($27.6m), specialised for deep-learning AI. A year later came Fire-Flyer II — a 1bn-yuan ($138m) system equipped with more than 10,000 Nvidia A100 graphics processors.
DeepSeek’s debut model, released in November 2023, immediately demonstrated performance on a par with GPT-4 and was made freely available for researchers and commercial users. By May 2024 the firm launched DeepSeek-V2; its aggressive pricing forced giants such as ByteDance, Tencent, Baidu and Alibaba to cut prices for their AI offerings. DeepSeek remained profitable as rivals booked losses.
In December 2024 the company unveiled DeepSeek-V3, which in tests outperformed the latest from OpenAI and Anthropic. Building on it, the firm created DeepSeek-R1 and its derivatives — the backbone of the much-discussed service.
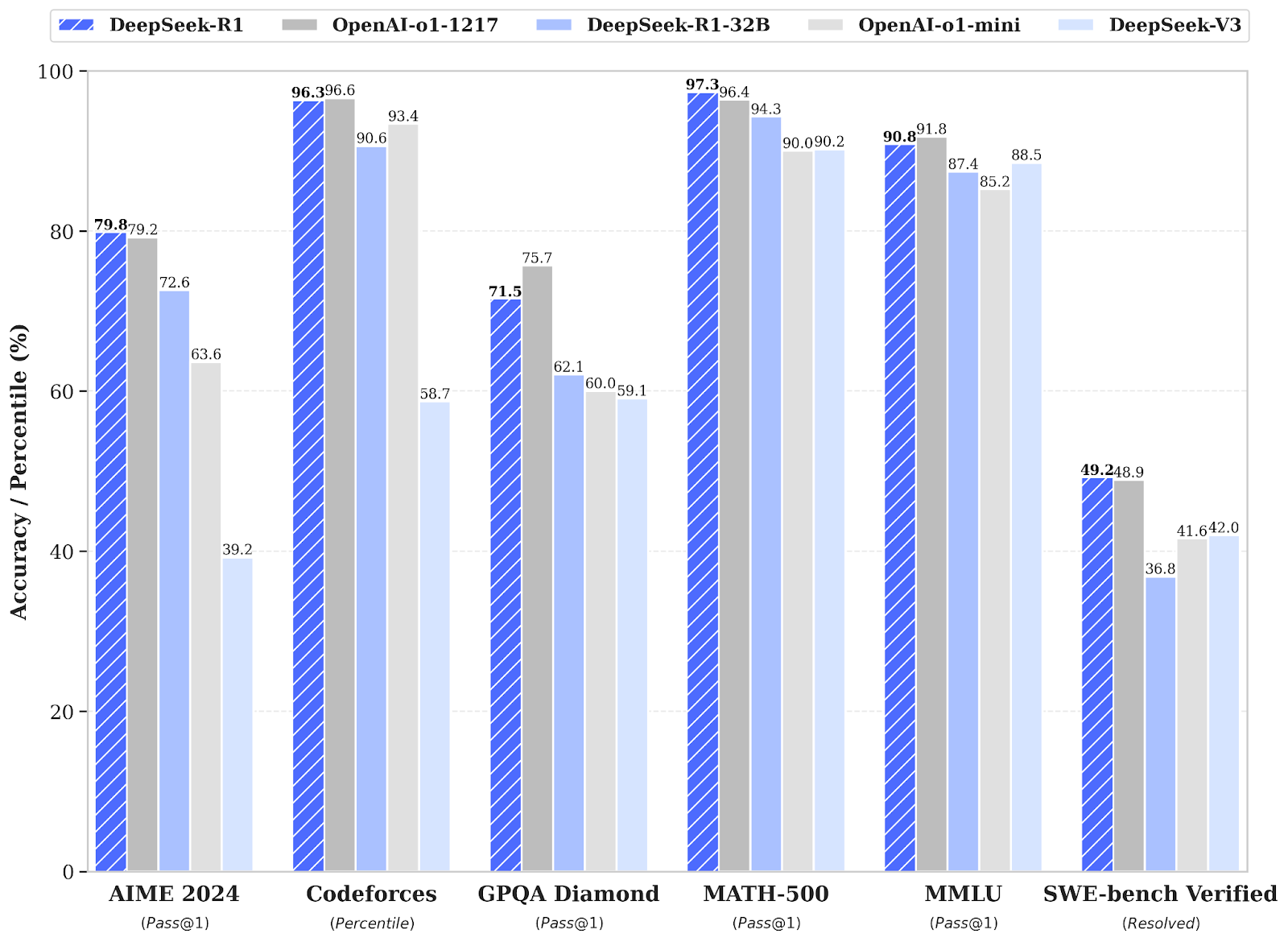
The chief advantage of the new model is its strikingly low cost of use. Processing 1m tokens with DeepSeek costs just $2.19, whereas OpenAI charges $60 for a comparable volume.
Behind the breakthrough: how DeepSeek‑R1 works
According to the published study, DeepSeek-R1 is built on reinforcement learning and “cold start” methods. That helped it reach exceptional performance in maths, coding and logical reasoning.
A key feature is the Chain of Thought approach, which breaks hard problems into sequential steps, mimicking human reasoning. The system analyses a task, divides it into stages and checks each step for errors before producing a final answer.
The technical execution is notably efficient. DeepSeek-R1 was trained on a system of 2,048 Nvidia H800 accelerators, consuming about 2.788m GPU hours. Optimisation comes from FP8 mixed precision and Multi-Token Prediction, which materially lowers hardware demands.
The model’s architecture comprises 671bn parameters. Uniquely, only 37bn of them are activated per pass. A Mixture of Experts enables scaling without a proportional rise in compute costs.
Also noteworthy is the Group Relative Policy Optimization (GRPO) method. It lets the model train without a critic, markedly improving efficiency.
As Jim Fan, a senior research manager at Nvidia, noted, this recalls the AlphaZero breakthrough from Google DeepMind, which learned to play Go and chess “without prior imitation of human grandmaster moves.” In his words, this is “the most important takeaway from the research paper.”
A new way to train language models
DeepSeek’s training strategy is especially striking. Unlike other leading LLMs, R1 did not undergo conventional “pretraining” on human-labelled data. The researchers found a way for the model to develop its own reasoning abilities almost from scratch.
“Instead of explicitly teaching the model how to solve problems, we simply provide it with the right incentives, and it autonomously develops cutting-edge strategies,” the study says.
The model also signals a new AI paradigm: rather than simply piling on training compute, the focus shifts to how much time and resource the model spends thinking before generating an answer. This scaling of test-time compute distinguishes the new class of “reasoning models” such as DeepSeek R1 and OpenAI‑o1 from their predecessors.
A critical look at the DeepSeek breakthrough
DeepSeek’s success has raised many questions among professionals. Scale AI chief executive Alexandr Wang claims the company has 50,000 Nvidia H100 chips, which would run counter to American export curbs.
“As I understand it, DeepSeek has 50,000 H100s […]. They cannot talk about them [publicly] because that contradicts US export controls,” Wang said.
After the restrictions were introduced, the price of smuggled H100s in China soared to $23,000–30,000, implying such a cluster would cost $1bn–1.5bn.
Bernstein analysts doubt the stated $5.6m cost of training the V3 model and note the absence of figures for developing R1. In the view of Peel Hunt’s Damindu Jayaweera, the public numbers capture only GPU-hours, ignoring other material expenses.
“It was trained in under 3 million GPU hours, which corresponds to a training cost of a little over $5 million. By comparison, analysts estimate that training the latest large AI model from Meta cost $60–70 million,” Jayaweera said.
The politics also raise concerns. The participation of founder Liang Wenfeng in a closed symposium chaired by China’s premier, Li Qiang, may point to a strategic role for the company in overcoming export curbs and bolstering the country’s technological self‑sufficiency.
“There is a high likelihood that DeepSeek and many other large Chinese companies are supported by the Chinese government not only in monetary terms,” — said Edward Harris, chief technology officer of Gladstone AI, which works closely with the US government.
There are also the model’s built‑in censorship mechanisms in the API version of R1, especially around politically sensitive topics for China. The model refuses to discuss the Tiananmen Square events, human rights in China or Taiwan’s status, substituting generated answers with stock evasions.
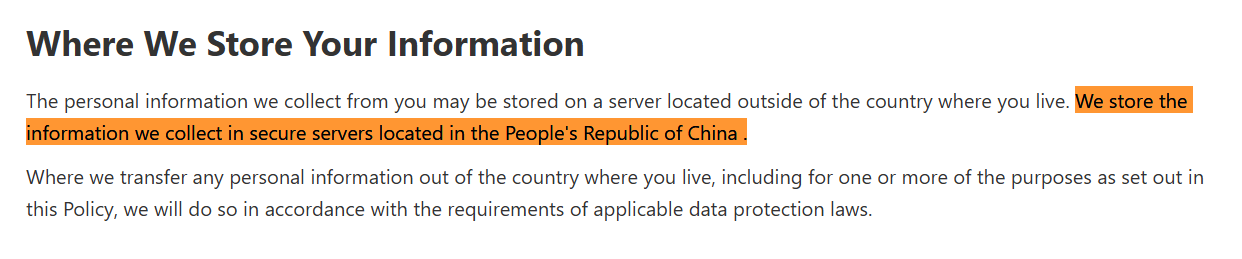
Data privacy is another worry. According to DeepSeek’s policy, users’ personal information is stored on servers in China, potentially exposing the firm to the same sort of problems that beset TikTok. The issue may be particularly acute in the US market, where regulators have already shown heightened attention to Chinese technology companies in the context of personal‑data protection.
The future of language models after DeepSeek
Controversies aside, DeepSeek’s achievements should not be underestimated. Test results indicate that R1 does outperform American peers on many measures. As Alexandr Wang put it, it is “a wake up call for America”, demanding faster innovation and tighter export controls on critical components.
Although OpenAI still leads the field, DeepSeek’s emergence is reshaping the market for models and infrastructure. If the official numbers hold up, the Chinese company has built a competitive system at far lower cost through innovation and optimisation — a challenge to the brute-force scaling of compute embraced by many rivals.
Interest in DeepSeek’s techniques is growing: Meta has already set up four “war rooms” to study Chinese models, hoping to fold the lessons into its open-source Llama ecosystem.
Some experts see DeepSeek’s success less as a threat to American technological dominance than as a sign of an emerging multipolar AI world. As former OpenAI policy staffer Miles Brundage noted:
“China will still get its own superintelligence(s) no more than a year later than the US, if there isn’t a war. So if you don’t want (literally) war, you need a vision for how to navigate multipolar AI outcomes.”
We appear to be at the start of a new era in artificial intelligence, where efficiency and optimisation may matter more than sheer computational muscle.
Рассылки ForkLog: держите руку на пульсе биткоин-индустрии!