




- Google has launched Gemini 2.0 Pro Experimental, the most advanced model in its lineup.
- The “thinking” Gemini 2.0 Flash Thinking is now available in the AI assistant app.
- Gemini 2.0 Flash now features an economical and optimized Lite version.
- Researchers from Stanford and the University of Washington created a reasoning neural network for $50 using responses from Gemini 2.0 Flash Thinking Experimental.
Google has introduced its new flagship AI model, Gemini 2.0 Pro Experimental. Additionally, it has made the “thinking” neural network Gemini 2.0 Flash Thinking available in the Gemini app.
Today we’re expanding the Gemini 2.0 family with new options and broader availability.
This builds on the first model we launched in December: 2.0 Flash, our model with low latency and better performance ⚡
Read more on today’s launches ⬇️ pic.twitter.com/SRpDIJMhUP
— Google (@Google) February 5, 2025
Gemini 2.0 Pro Experimental is the successor to Gemini 1.5 Pro. It is available on platforms such as Vertex AI, Google AI Studio, and to Advanced subscribers in the Gemini app. The company highlighted the neural network’s strong skills in programming and handling complex queries. It “better understands and contemplates knowledge about the world.”
The professional version’s context window is 2 million tokens. It can comprehend all seven Harry Potter books at once, leaving about 400,000 words in reserve.
Gemini 2.0 Flash now features the most economical and optimized Lite version.
The performance of the Gemini 2.0 series shows significant improvement over 1.5 in various benchmarks.



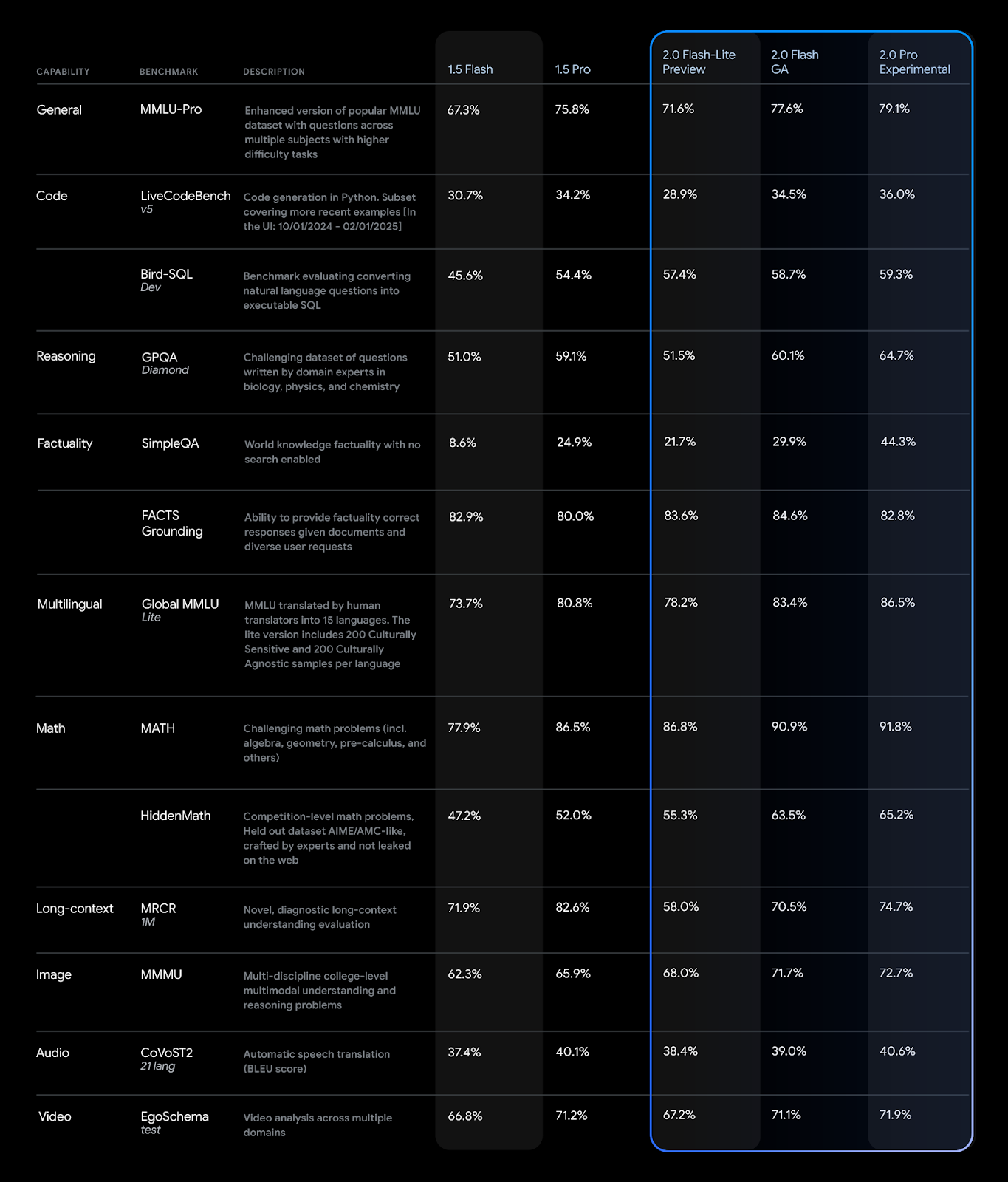
The company has reduced the output cost for Flash and Flash-Lite, setting it lower than Gemini 1.5 Flash, while improving performance.


The hype around the inexpensive and efficient Chinese AI model DeepSeek-R1 has raised questions about the necessity of billion-dollar investments in artificial intelligence. A race to reduce the cost of neural networks has begun.
A Reasoning AI Model for $50
In January, NovaSky introduced an open-source thinking AI model, Sky-T1, which cost only $450 to train.
Researchers from Stanford and the University of Washington went further, managing to train a reasoning AI for less than $50. The s1 model shows results similar to o1 from OpenAI and R1 from DeepSeek in tests. It is available on GitHub along with the data and code used for training.
The project team based their work on an existing foundational neural network and refined it through distillation—a process where reasoning capabilities are extracted from another AI model by training on its responses.
The s1 is based on a small, free AI model, Qwen, from Alibaba. Researchers created a dataset consisting of 1,000 carefully selected questions and answers from Gemini 2.0 Flash Thinking Experimental.
Training using 16 Nvidia H100 GPUs took less than 30 minutes.
Is Distillation Ethical?
The idea of launching advanced AI models without million-dollar investments might seem exciting. However, major labs are likely displeased with this approach.
OpenAI accused DeepSeek of unlawfully collecting data from its API for distillation.
The developers of s1 aimed to find the simplest way to achieve high performance. They used the Supervised Fine-Tuning (SFT) approach, where the model is instructed to mimic certain behavior in a dataset.
SFT is cheaper than large-scale reinforcement learning.
Google offers free access to Gemini 2.0 Flash Thinking Experimental on the Google AI Studio platform.
Major Investments Still Needed
Despite the buzz around inexpensive neural networks, tech giants are not rushing to cut back on investments in training new models.
Meta, Google, and Microsoft intend to maintain billion-dollar investments in AI infrastructure.
Distillation has proven to be a good method for refining models, but it does not create new neural networks capable of significantly surpassing the solutions available today.
Back in January, Donald Trump announced $500 billion in private sector investments in artificial intelligence infrastructure.