

What are transformers? (machine learning)

What are transformers?
Transformers are a relatively new type of neural network designed to handle sequences while coping easily with long-range dependencies. Today they are the most advanced technique in natural-language processing (NLP).
They can translate text, write poems and articles, and even generate computer code. Unlike recurrent neural networks (RNNs), transformers do not process sequences strictly in order. For example, if the input is text, they do not need to process the end of a sentence only after the beginning. This makes such networks easy to parallelise and much faster to train.
When did they appear?
Transformers were first described by engineers at Google Brain in the 2017 paper “Attention Is All You Need”.
One key difference from earlier methods is that the input sequence can be fed in parallel, allowing efficient use of graphics processors and higher training speeds.
Why use transformers?
Until 2017, engineers used deep learning to understand text via recurrent neural networks.
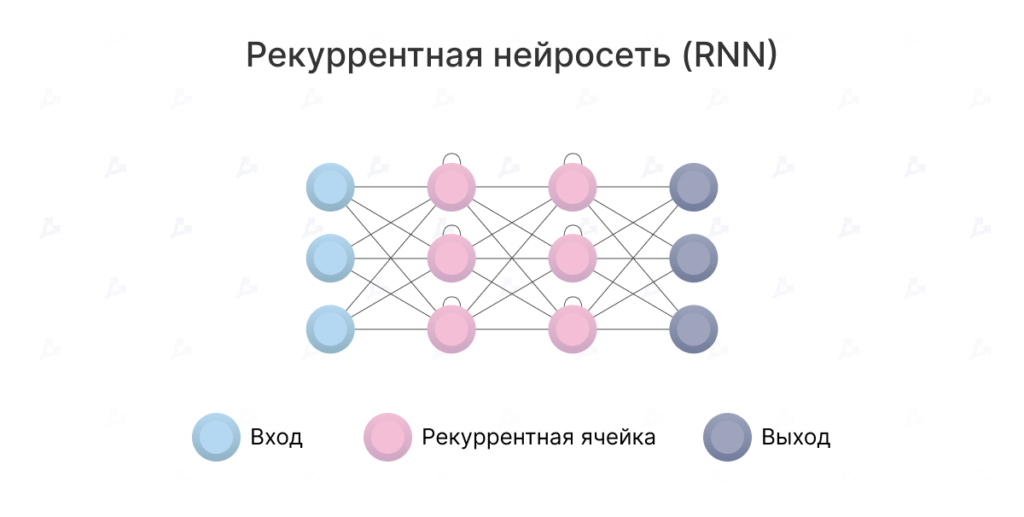
Suppose we are translating a sentence from English into Russian. An RNN would take the English sentence as input, process its words one by one, and then output their Russian counterparts sequentially. The crucial word here is “sequential”. Word order matters in language; you cannot simply shuffle words.
RNNs run into several problems. First, they try to process long sequences of text. By the time they reach the end of a paragraph, they can “forget” the beginning. For instance, a translation model based on RNNs may struggle to remember the gender of an entity in a long passage.
Second, RNNs are hard to train. They suffer from the so-called vanishing/exploding gradient problem.
Third, because they process words sequentially, they are difficult to parallelise. That means you cannot easily speed up training by using more graphics processors. Consequently, training on very large datasets is impractical.
How do transformers work?
The main components of transformers are an encoder and a decoder.
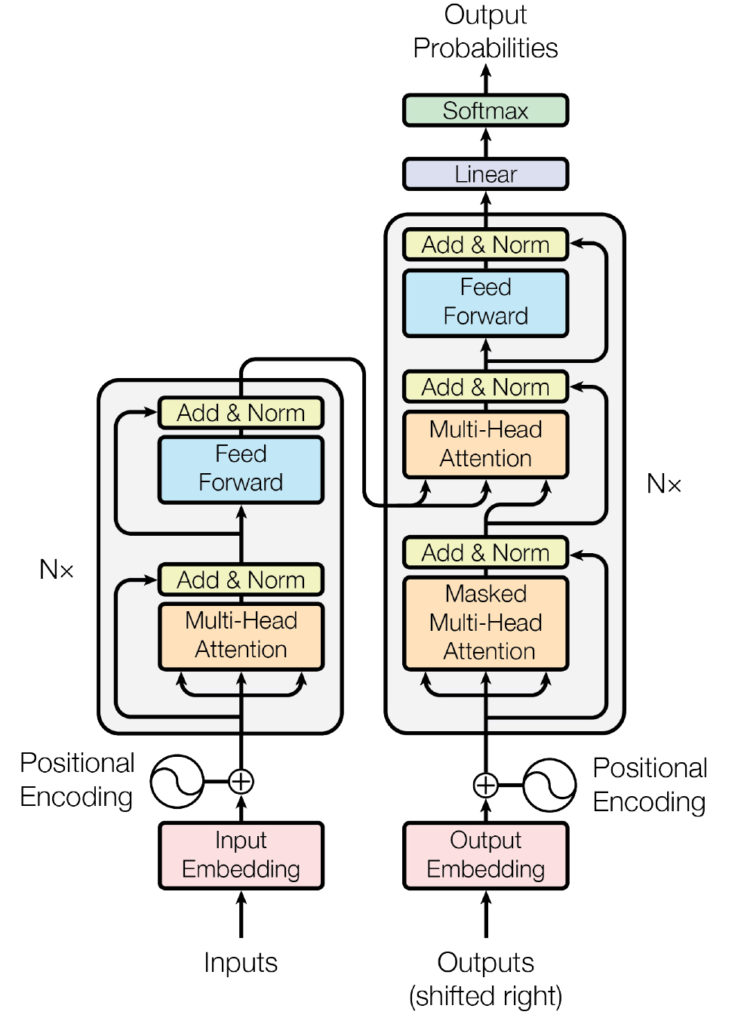
The encoder transforms the input (for example, text) into a vector (a set of numbers). The decoder then renders it as a new sequence (for example, an answer) or as words in another language, depending on the model’s purpose.
Other innovations behind transformers boil down to three core ideas:
- positional encodings;
- attention;
- self-attention.
Start with positional encodings. Suppose we need to translate English text into Russian. Standard RNN models “understand” word order and process words sequentially. But that hampers parallelisation.
Positional encoders overcome this. The idea is to take every word in the input sequence—here, the English sentence—and add to each its position. You “feed” the network a sequence like this:
[(“Red”, 1), (“fox”, 2), (“jumps”, 3), (“over”, 4), (“lazy”, 5), (“dog”, 6)]
Conceptually, this shifts the burden of understanding word order from the network’s structure onto the data themselves.
At first, before training on any data, transformers do not know how to interpret these positional codes. But as the model sees more examples of sentences and their encodings, it learns to use them effectively.
The sketch above is simplified— the original paper used sinusoidal functions to construct positional encodings rather than plain integers 1, 2, 3, 4— but the point is the same. By keeping word order as data rather than structure, the network becomes easier to train.
Attention is a neural-network mechanism introduced to machine translation in 2015. To grasp it, consider the original paper.
Imagine we need to translate into French the phrase:
“The agreement on the European Economic Area was signed in August 1992”.
The French equivalent is:
“L’accord sur la zone économique européenne a été signé en août 1992”.
The worst way to translate would be to look up word-for-word correspondences in order. That fails for several reasons.
First, some words are reordered in French:
“European Economic Area” versus “la zone économique européenne”.
Second, French marks gender. To match the feminine noun “la zone”, the adjectives “économique” and “européenne” must also take the feminine form.
Attention helps avoid such pitfalls. It lets a text model “look” at each word in the source sentence when deciding how to translate. This is illustrated in a visualisation from the original paper:

This is a kind of heat map showing what the model “pays attention to” when translating each word in the French sentence. As expected, when the model outputs “européenne”, it heavily considers both input words— “European” and “Economic”.
Training data teach the model which words to “attend” to at each step. By observing thousands of English and French sentences, the algorithm learns interdependent word types. It learns to account for gender, plurality and other grammatical rules.
Attention has been hugely useful for NLP since 2015, but in its original form it was paired with recurrent networks. The 2017 transformer paper’s innovation was in part to dispense with RNNs entirely— hence the title “Attention Is All You Need”.
The last ingredient is a twist on attention called “self-attention”.
If attention helps align words when translating between languages, self-attention helps a model grasp meaning and patterns within a language.
Consider two sentences:
«Николай потерял ключ от машины»
«Журавлиный ключ направился на юг»
The word «ключ» here means two very different things, which humans can easily tell apart from context. Self-attention allows a network to understand a word in the context of its neighbours.
Thus, when the model processes «ключ» in the first sentence, it can attend to «машины» and infer this is a metal key for a lock, not something else.
In the second sentence, the model can attend to «журавлиный» and «юг» to relate «ключ» to a flock of birds. Self-attention helps neural networks resolve ambiguity, perform part-of-speech tagging, learn semantic roles and more.
Where are they used?
Transformers were initially pitched as networks for processing and understanding natural language. In the four years since their debut they have gained popularity and now underpin many services used daily by millions.
One of the simplest examples is Google’s BERT language model, introduced in 2018.
On October 25th 2019 the tech giant announced it had begun using the algorithm in the English-language version of its search engine in the United States. A month and a half later, the company expanded support to 70 languages, including Russian, Ukrainian, Kazakh and Belarusian.
The original English model was trained on the BooksCorpus dataset of 800m words and on Wikipedia articles. Base BERT had 110m parameters; the larger version had 340m.
Another popular transformer-based language model is OpenAI’s GPT (Generative Pre-trained Transformer).
Today the most up-to-date version is GPT-3. It was trained on a dataset of 570GB and has 175bn parameters, making it one of the largest language models.
GPT-3 can generate articles, answer questions, power chatbots, perform semantic search and produce summaries.
GitHub Copilot, an AI assistant for automatic code writing, was also built on GPT-3. It uses a special GPT-3 variant, Codex AI, trained on code. Researchers have estimated that since its August 2021 release, 30% of new code on GitHub has been written with Copilot’s help.
Beyond that, transformers are increasingly used in Yandex services such as Search, News and Translate, in Google products, in chatbots and more. Sber has released its own GPT modification trained on 600GB of Russian-language text.
What are the prospects for transformers?
Transformers’ potential is far from exhausted. They have proved themselves on text, and lately this class of network has been explored for other tasks such as computer vision.
In late 2020, CV models showed strong results on popular benchmarks such as object detection on the COGO dataset and image classification on ImageNet.
In October 2020 researchers at Facebook AI Research published a paper describing Data-efficient Image Transformers (DeiT), a transformer-based model. They said they had found a way to train the algorithm without a huge labelled dataset and achieved 85% image-recognition accuracy.
In May 2021 specialists at Facebook AI Research presented DINO, an open-source computer-vision algorithm that automatically segments objects in photos and videos without manual labelling. It is also based on transformers, and reached 80% segmentation accuracy.
Thus, beyond NLP, transformers are increasingly finding use in other tasks as well.
What risks do transformers pose?
Alongside obvious advantages, transformers in NLP carry risks. The creators of GPT-3 have repeatedly stated that the network could be used for mass spam, harassment or disinformation.
Language models are also prone to bias against certain groups. Although the developers have reduced GPT-3’s toxicity, they are still not ready to grant broad access to the tool.
In September 2020 researchers at a college in Middlebury published a report on the risks of radicalisation associated with the spread of large language models. They noted that GPT-3 shows “significant improvements” in generating extremist texts compared with its predecessor, GPT-2.
The technology has also drawn criticism from one of the “fathers of deep learning”, Yann LeCun. He said that many expectations about the capabilities of large language models are unrealistic.
“Trying to build intelligent machines by scaling up language models is like building airplanes to fly to the Moon. You may break altitude records, but flying to the Moon will require a completely different approach,” wrote LeCun.
Рассылки ForkLog: держите руку на пульсе биткоин-индустрии!