




What is a neural network?
An artificial neural network is a mathematical model inspired by the biological neural networks that make up the brains of living beings. Such systems learn to perform tasks by studying examples rather than being explicitly programmed for a specific application.
They deliver state-of-the-art performance in fields such as speech and image recognition, working with unstructured data like recorded audio and photographs.
How do neural networks differ from AI and ML?
Artificial intelligence is a broad field of computer science focused on creating intelligent machines capable of performing cognitive tasks.
Machine learning, a subfield of AI, solves problems not by hard-coding rules but by finding patterns in data after training an algorithm on many examples.
Neural networks are a subset of machine learning. As noted above, they make predictions from unstructured data.
What is a neural network made of?
Like its biological counterpart, an artificial neural network consists of neurons and synapses.
A neuron is a unit that receives information and performs computations on it. It is the simplest structural element of any neural network. Neurons are typically arranged in layers that together form the network.
Most neurons operate in broadly similar ways, though some variants serve specific functions.
Core types of neurons:
- input — the layer of neurons that receives information;
- hidden — one or more layers that process information;
- output — the layer that represents the result of the computation.
A synapse is a connection that links the output of one neuron to the input of another. Signals passing through it can be amplified or attenuated.
A synapse has a parameter called a weight—a coefficient that scales the information transmitted between neurons.


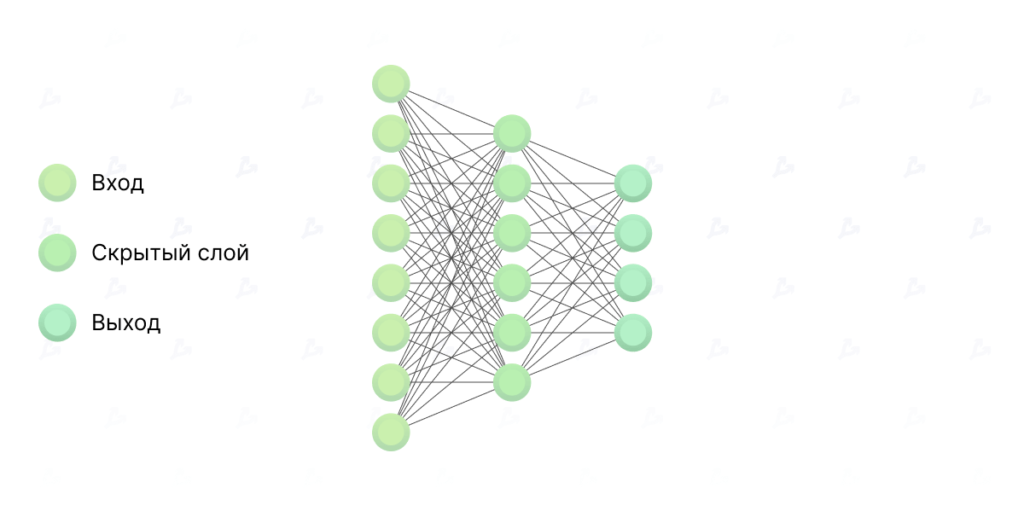
Activation functions play a crucial role in a network’s architecture. As in living brains, they determine which signals pass through neurons and which do not.
For example, when you grasp a hot kettle, nerve endings in your fingers relay information to neurons in the brain, where an activation function decides whether to pull your hand away from the heat or keep transmitting signals.
How does a neural network work?
Information enters the input layer, then flows via synapses to the next layer. Each synapse has its own weight, and any neuron in a subsequent layer may have multiple inputs. The signal propagates until it reaches the final output.
Consider handwritten-digit recognition: the algorithm must cope with great variation in how data are represented. Each digit from 0 to 9 can be written in many ways; the size and exact shape of each symbol vary by writer and circumstance.
The input layer receives values representing the pixels of an image of a digit. The output layer, in turn, predicts which symbol is shown.
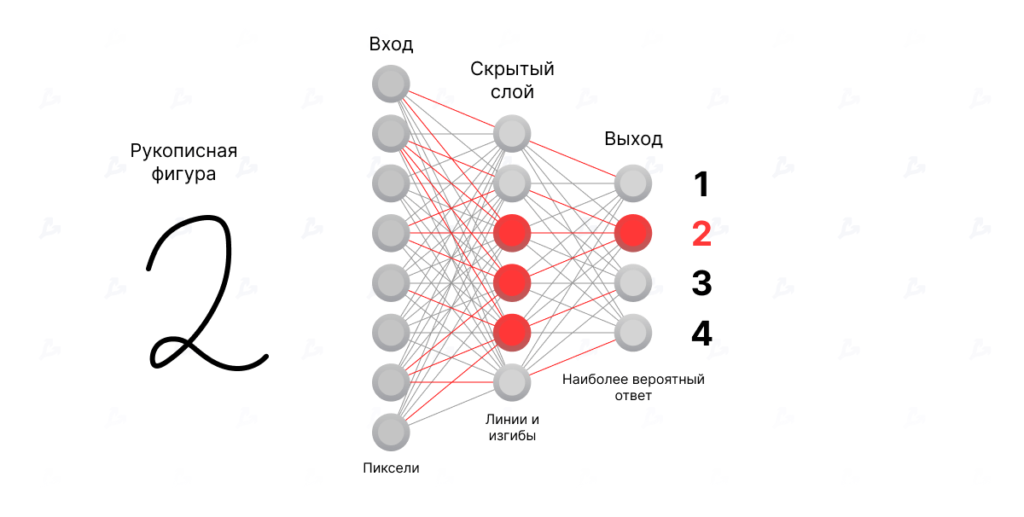
The circles in the diagram are neurons, organised into vertically stacked, interconnected layers.
The links are coloured to indicate the importance of connections between neurons. Red links strengthen the value as it moves between layers, increasing the chance of activating the recipient neuron.
Activated neurons are shaded red. In “Hidden layer 1”, they indicate that the image contains a particular combination of pixels resembling the horizontal stroke at the top of a handwritten 3 or 7.
Thus Hidden layer 1 can detect characteristic lines and curves that ultimately combine into a complete handwritten figure.
How does a neural network learn?
During training, the model learns which connections matter for accurate predictions. At each step it uses a mathematical function to gauge how close its latest prediction was to the expected result.
This function produces error values the system uses to calculate how to update the weights attached to each link, with the aim of improving accuracy.
Over many training cycles, with occasional manual tuning of parameters, the network generates ever more accurate predictions until performance plateaus. At that point—for example, when handwritten digits are recognised with accuracy above 95%—the network can be considered trained.
What is a dataset?
A dataset is a collection of homogeneous data used to train neural networks. To train a face-recognition algorithm, for instance, it must be shown many photographs of people. The more data, the more accurate the model.
Datasets typically come in three types:
- training — used to fit the network;
- test — used to assess accuracy;
- validation — an independent set for a final evaluation of the algorithm’s accuracy.
Data can be of any format: tables, photos, video, audio and more. In supervised learning the data are often labelled with specialised software. Yet inaccuracies in datasets can lead to errors in the resulting models.
In April 2021 researchers at the Massachusetts Institute of Technology found that popular datasets contain many mistakes. In widely used benchmark sets, for example, a mushroom might be labelled as a spoon, a frog as a cat, and a high note by Ariana Grande in an audio file marked as a whistle.
Another MIT study showed that careless work by contractors on Amazon Mechanical Turk hampers the development of text-generation systems. They are paid per item labelled, so they tend to work quickly with little regard for accuracy.
Researchers therefore urge developers to practise data “hygiene”.
In reinforcement learning, data do not need labelling, as an agent must discover patterns in an environment and is rewarded when it achieves a goal.
Where are neural networks used?
Neural networks are used for many tasks: recognising and generating images, speech and language, and—combined with reinforcement learning—for games, from board games such as Go to video games like Dota 2 and Quake III.
Such systems underpin many online services. Amazon uses them to understand speech for its Alexa voice assistant; Microsoft uses them for real-time translation in the browser.
Every Google search query invokes several machine-learning systems to parse the language and personalise results.
Beyond the consumer web, they are spreading across industries, including:
- computer vision for autonomous cars, drones and delivery robots;
- speech recognition and synthesis, and language for chatbots and service robots;
- face identification in video-surveillance systems;
- assisting radiologists in spotting tumours on X-rays;
- helping researchers identify genetic sequences linked to disease and molecules that could improve drugs;
- predictive maintenance of infrastructure by analysing data from internet-of-things sensors, and much else.
What are the challenges or drawbacks of neural networks?
A major drawback is the volume of data required for training. Datasets can be vast: not long ago Facebook said it used one billion images to achieve record performance in image recognition.
Because of dataset size and the number of training cycles, powerful and costly hardware—typically with high-performance GPUs—is often needed. Whether you build your own system or rent cloud capacity, training incurs significant cost.
Another challenge is dataset noise. As noted, people make mistakes when creating datasets, which can affect the final result.
What types of neural network exist?
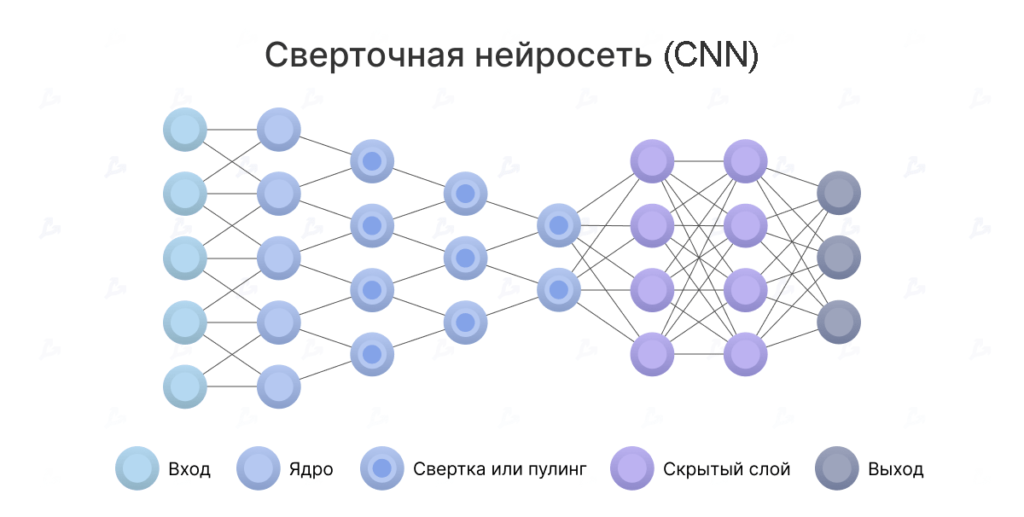
Roughly 30 types of neural network are in use, suited to different tasks. Convolutional neural networks (CNNs) are common in computer vision, while recurrent neural networks (RNNs) are used for language.
Each has its quirks. In CNNs, early layers specialise in extracting features from an image, which are then passed to a standard neural network to classify objects.
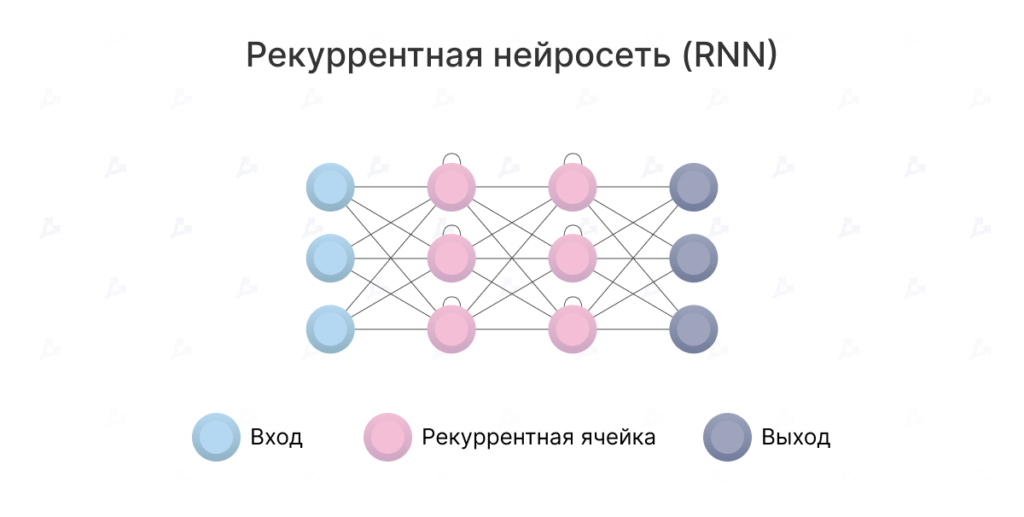
RNNs differ in that neurons receive information not only from the previous layer but also from a recurrent connection to themselves. This lets the network learn the sequence of inputs.
Their difficulty lies in the so-called vanishing-gradient problem: the network quickly forgets information over time. Although this affects the weights rather than the neurons’ states, information accumulates in those states.
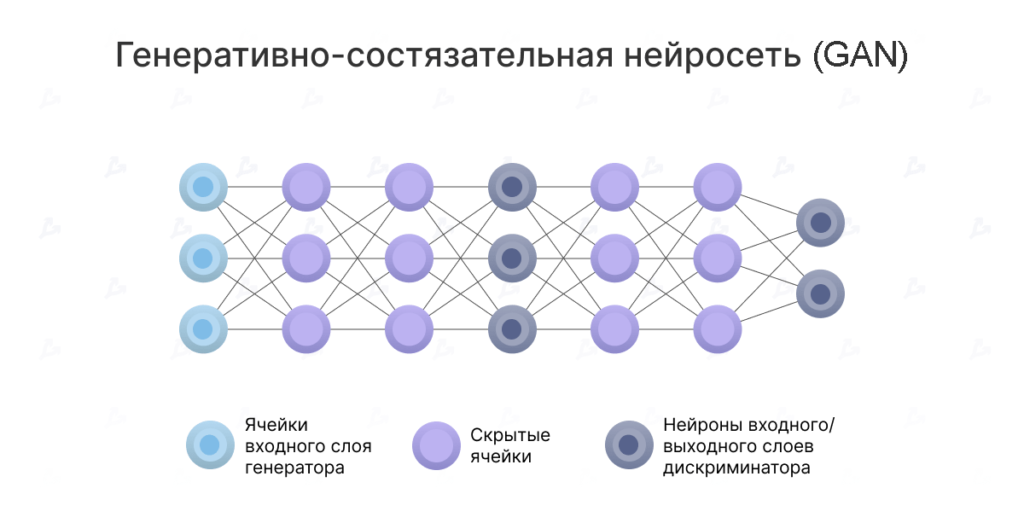
Generative adversarial networks (GANs) comprise two networks: a generator that creates content and a discriminator that evaluates it.
The discriminator receives either training data or data produced by the generator. Its success at guessing the source contributes to the error signal.
Thus a contest emerges: the generator learns to fool the discriminator, which in turn learns to detect the fraud. Training is difficult, as each network must be trained and balanced against the other.
Typical applications include photo stylisation, deepfakes, audio generation and more.
Will neural networks lead to artificial general intelligence?
Today, neural networks are used for narrow, specialised tasks—what is known as weak AI.
No models yet qualify as artificial general intelligence, capable of tackling as broad a range of tasks, with comparable understanding, as a human. When such systems will arrive is unknown: some forecasts put them within the next decade; others, not for 1,000 years.
Follow ForkLog news on Telegram: ForkLog AI — all the news from the world of AI!