




Chinese developer Kuaishou has unveiled the third version of its video-generation model, Kling AI.
🚀 Introducing the Kling 3.0 Model: Everyone a Director. It’s Time.
An all-in-one creative engine that enables truly native multimodal creation.
— Superb Consistency: Your characters and elements, always locked in.
— Flexible Video Production: Create 15s clips with precise… pic.twitter.com/CJBILOdMZs— Kling AI (@Kling_ai) February 4, 2026
“Kling 3.0 is built on a deeply unified training platform, providing truly native multimodal input and output. Thanks to seamless audio integration and advanced element consistency control, the model endows the generated content with a stronger sense of life and coherence,” the announcement says.
The model unifies several tasks: turning text, images and references into video; adding or removing content; and modifying and transforming clips.
Clip length has risen to 15 seconds. Other upgrades include more flexible shot control and tighter prompt adherence. Overall realism is improved: character movement is more expressive and dynamic.


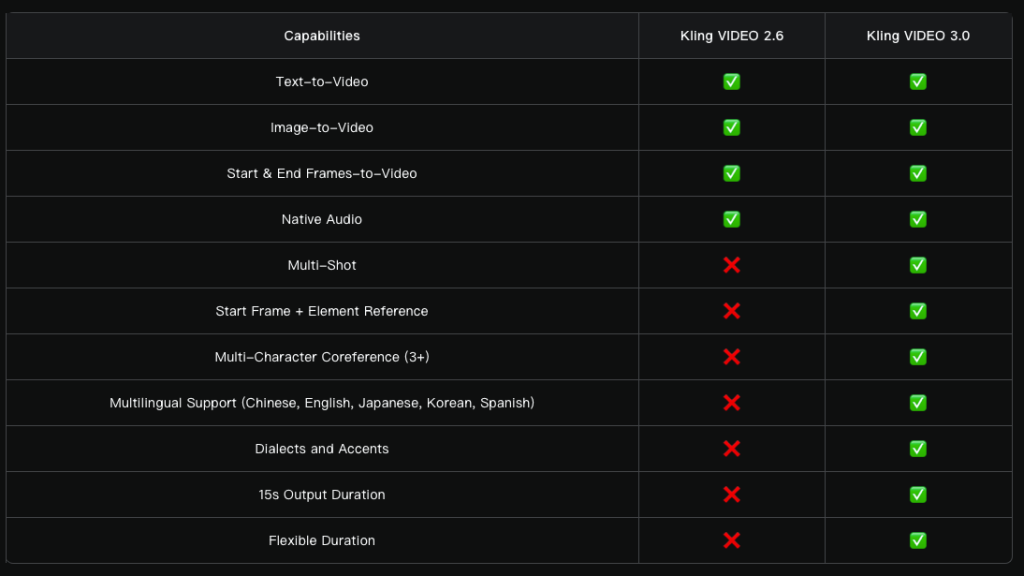
A new Multi-Shot feature analyses the prompt to infer scene structure and shot types. The tool automatically sets camera angles and composition.
The model supports editing patterns ranging from classic shot–reverse-shot dialogue to parallel storytelling and voice-over scenes.
“No more tedious cutting and editing — a single generation is enough to obtain a cinematic clip and make complex audiovisual forms accessible to all creators,” the announcement says.
Kling 3.0 is truly “one giant leap for AI video generation”! Check out this amazing mockumentary from Kling AI Creative Partner Simon Meyer! pic.twitter.com/Iyw919s6OJ
— Kling AI (@Kling_ai) February 5, 2026
Beyond standard image-to-video generation, Kling 3.0 accepts multiple reference images as well as source videos as scene elements.
The model locks in attributes of characters, objects and the scene. Regardless of camera movement and plot progression, key elements remain stable and consistent throughout the video.
Developers have refined native audio: the system syncs speech to facial movements more precisely and, in dialogue scenes, lets users manually designate the speaker.
The list of supported languages now includes Chinese, English, Japanese, Korean and Spanish. Dialects and accents are handled better too.
The team also upgraded its multimodal model O1 to Video 3.0 Omni.



Users can upload speech audio from three seconds to extract a voice, or record a three-to-eight-second video of a character to capture its core attributes.
Sora’s rivals close in
OpenAI unveiled the Sora video-generation model in February 2024. The tool wowed social networks, but a public release came only in December.
Nearly a year later, users gained access to text-to-video, “animating” images and extending existing clips.
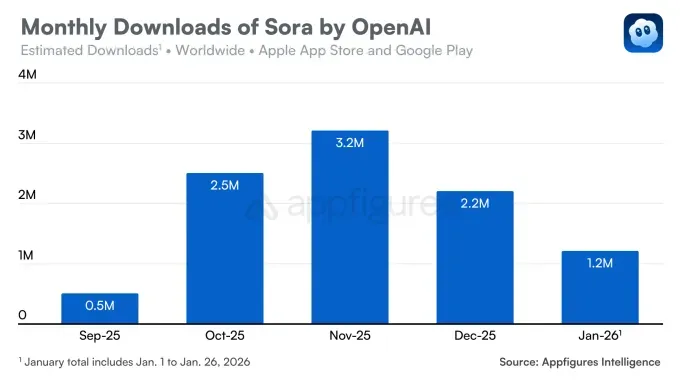
The Sora iOS app arrived in September and immediately drew attention: it was installed more than 100,000 times on day one. The service surpassed 1m downloads faster than ChatGPT, despite being invite-only.
The trend soon reversed. In December downloads fell 32% from the prior month. The slide continued in January, when the app was downloaded 1.2m times.



Several factors explain the slump. First, Google’s Nano Banana model intensified competition, bolstering Gemini’s position.
Sora also competes with Meta AI and its Vibes feature. In December, startup Runway amplified the pressure with its Gen 4.5 model, which outperformed peers in independent tests.
Second, OpenAI’s product ran into copyright troubles. Users created videos with popular characters such as “SpongeBob” or “Pikachu”, forcing the company to tighten restrictions.
In December the situation stabilised after a deal with Disney allowed users to generate videos with the studio’s characters. Even so, downloads did not rebound.
In October, deepfakes featuring Sam Altman flooded Sora.