

What is natural-language processing?

What is natural-language processing?
Natural-language processing (NLP) is a set of methods that help a computer system understand human speech.
NLP is a branch of artificial intelligence. It remains one of AI’s hardest problems and is still far from fully solved.
When did NLP emerge?
The roots of NLP go back to the 1950s, when the British scientist Alan Turing published the essay “Computing Machinery and Intelligence”, proposing the “Turing test”. One of its criteria is a machine’s ability to interpret and generate human speech.
On January 7th 1954, researchers at Georgetown University demonstrated machine translation. Engineers translated more than 60 Russian sentences into English fully automatically. The event spurred the field and went down in history as the Georgetown experiment.
In 1966, the American computer scientist of German origin Joseph Weizenbaum, at MIT, built the first chatbot, ELIZA. The program mimicked a conversation with a psychotherapist using active-listening techniques.
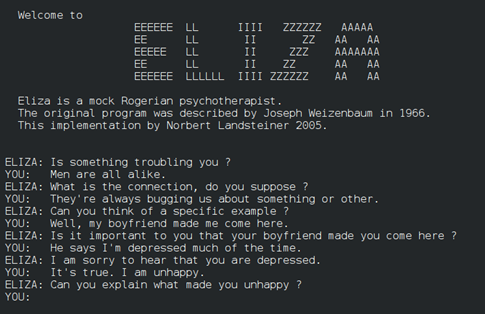
In essence, the system paraphrased the user’s messages to create the impression of understanding. In reality it did not grasp the substance of the dialogue. When it could not find an answer, it typically replied “I see” (“Понятно”) and steered the conversation elsewhere.
That same year the Automatic Language Processing Advisory Committee (ALPAC) released a report concluding that a decade of research had fallen short. Funding for machine translation was sharply cut.
For the next decades breakthroughs were scarce, until the rise of the first machine-learning algorithms in the 1980s. Around the same time, statistical machine-translation systems appeared and research resumed.
NLP boomed in the 2010s as deep-learning algorithms took off. Many of today’s mainstays appeared then—chatbots, autocorrect, voice assistants and the like. Recurrent neural networks became the default tool for many tasks.
Another revolution came in 2019, when OpenAI unveiled the language model Generative Pre-Trained Transformer 2, or GPT-2. Unlike earlier generators, it could produce long, coherent passages, answer questions, compose verse and even suggest new recipes.
A year later OpenAI introduced GPT-3, and big technology firms began showcasing their own large language models.
How do NLP systems work?
To answer that, consider how we humans use natural language.
When we hear or read a phrase, several processes occur in parallel:
- perception;
- understanding of meaning;
- response.
Perception is the conversion of a sensory signal into symbols. We might hear a particular word or see it rendered in different fonts. Either way, the input must be turned into a single representation: words written with letters.
Understanding meaning is the hardest task—one that even people with their natural intelligence often mishandle. Lacking context or misreading a phrase can cause confusion, even serious conflict.
For example, in 1956, at the height of the Cold War between the USSR and the United States, Soviet leader Nikita Khrushchev delivered a speech that contained the phrase “We will bury you.” Americans took it too literally, construing it as a threat of nuclear attack. In fact, Khrushchev meant only that socialism would outlive capitalism; the phrase was an interpretation of a thesis by Karl Marx.
The incident quickly escalated into an international scandal, prompting apologies from Soviet diplomats and the Communist Party’s general secretary.
Hence the importance of grasping meaning and context—spoken or written—to avoid situations that can affect people’s lives.
A response is the outcome of decision-making. It is comparatively simple: form a set of possible replies based on the perceived meaning, the context and, perhaps, internal states.
NLP algorithms follow much the same pattern.
Perception is the conversion of incoming information into a machine-readable set of symbols. For a chatbot, text is already in that form. For audio or handwriting, it must first be converted—something modern neural networks do well.
Responding to text has also been solved by weighing alternatives and comparing results. A chatbot may return a text answer from its knowledge base; a voice assistant may act on a smart-home device—say, switching on a light.
Understanding is trickier, and worth considering separately.
How do AI systems understand speech?
Today, three approaches to language understanding are common:
- statistical;
- formal-grammatical;
- neural.
Statistical methods are widely used in machine translation, automated reviewers and some chatbots. The idea is to feed a model huge corpora of text to uncover statistical regularities. Such models are then used to translate or generate text, sometimes with an awareness of context.
The formal-grammatical approach is a mathematical apparatus that aims to determine the meaning of a natural-language phrase as precisely and unambiguously as a machine can. This is not always possible: some phrases are unclear even to people.
For rich languages such as Russian or English, a precise, detailed mathematical description is extremely difficult. Formal methods are therefore more often used for syntactic analysis of artificial languages, which are designed to remove ambiguity.
In the neural approach, neural networks in deep learning are used to recognise the meaning of an input phrase and generate a response. They are trained on stimulus–response pairs, where the stimulus is a natural-language phrase and the response is the system’s reply in the same language or some action by the system.
It is a highly promising approach, but it also inherits all the drawbacks of neural networks.
What are NLP systems used for?
NLP systems address many tasks, from building chatbots to analysing vast document collections.
Core NLP tasks include:
- text analysis;
- speech recognition;
- text generation;
- text-to-speech.
Text analysis is the intelligent processing of large volumes of information to find patterns and similarities. It includes information extraction, search, sentiment analysis, question–answering and opinion mining.
Speech recognition converts audio or spoken language into digital information. A simple example: when you address Siri, the algorithm recognises speech in real time and converts it into text.
Text generation is the creation of text using computer algorithms.
Text-to-speech is the reverse of speech recognition—for instance, voice assistants reading information from the internet.
Where are NLP technologies applied?
There are many everyday uses of NLP technologies:
- email services use Bayesian spam filtering, a statistical NLP method that compares incoming messages with a database to identify junk mail;
- text editors such as Microsoft Word or Google Docs use language processing to correct not only grammatical errors but also context-specific ones;
- virtual keyboards on modern smartphones can predict subsequent words given sentence context;
- voice assistants such as Siri or Google Assistant can recognise users, execute commands, transcribe speech, search the internet, control smart-home devices and more;
- accessibility apps on PCs and smartphones can read aloud text and interface elements for the visually impaired thanks to speech-synthesis algorithms;
- large language models with vast numbers of parameters, such as GPT-3 or BERT, can generate texts of varying length and genre, assist with search and predict a sentence from its first few words;
- machine-translation systems use statistical and language models to translate texts between languages.
What difficulties arise when using NLP technologies?
Tasks in NLP have often relied on recurrent neural networks, which suffer from several drawbacks, including:
- sequential word processing;
- an inability to retain large amounts of information;
- susceptibility to the vanishing/exploding-gradient problem;
- the inability to process information in parallel.
Beyond that, popular methods often misread context, requiring careful additional tuning.
Large language models address many of these issues, but they bring challenges of their own—chiefly accessibility. Training a large model such as GPT-3 or BERT is difficult, though big companies have increasingly released them openly.
Many models also work only with popular languages, ignoring rarer dialects. That affects a system’s ability to recognise diverse accents.
In text processing via optical character recognition, many algorithms still struggle with handwriting.
Beyond technical shortcomings, NLP can be misused. In 2016, Microsoft launched the chatbot Tay on Twitter, which learned from its human interlocutors. After just 16 hours the company shut the bot down after it began posting racist and offensive tweets.
In 2021, fraudsters in the UAE faked the voice of a company executive and convinced a bank employee to transfer $35m to their accounts.
A similar case occurred in 2019 with a British energy firm, where scammers stole about $243,000 by impersonating the CEO with a synthetic voice.
Large language models can be used for mass spam, harassment or disinformation. The creators of GPT-3 warned about this. They also said their model exhibits biases toward certain groups. However, OpenAI said it had reduced GPT-3’s toxicity and, at the end of 2021, granted broader developer access and allowed customisation.
Subscribe to ForkLog on Telegram: ForkLog AI — all the news from the world of AI!
Рассылки ForkLog: держите руку на пульсе биткоин-индустрии!