

Как понять ценность распределенных реестров без биткоина
Автор данного материала Ричард Браун — исполнительный архитектор по вопросам инноваций, банкинга и финансовых рынков в IBM UK, а также консультант по вопросам криптовалюты и децентрализации в таких компаниях, как Hyperledger, Chromaway, Elliptic Enterprises и DLG. Взгляды и суждения, высказанные в статье, принадлежат автору, и необязательно соответствуют взглядам, а также не должны приписываться, редакции ForkLog.
Для объяснения важности распределённого реестра совсем необязательно использовать «цифровые валюты»
В этой статье объясняется суть распределённого реестра с самых его основ — таким образом, она является в некотором смысле обучающей, и предназначена для тех, кто предпочитает постигать новые технологии в связке с бизнес-вопросами реального мира, а не сразу получать готовое решение — в особенности это касается профессионалов финансовой отрасли. Поэтому в данной статье ни разу не упоминаются цифровые валюты — оказывается, они совершенно не нужны для того, чтобы понять важность технологии распределённого реестра.
Для начала — банковские системы
В дальнейшем для примера будут использоваться банковские депозиты и платежи — но та же самая логика работает и в других областях, что ещё будет обсуждаться позднее.
Подумайте о нынешних банковских системах. Представьте себе, что в мире есть три банка: А, В и С, а также два клиента — клиент А и клиент В. В каждом банке своя IT-система, которая используется для контроля счетов. В целом эта ситуация весьма напоминает существующую. Система банка А записывает данные по счетам клиентов банка А, система банка В — по счетам клиентов банка В, и так далее. На рисунке это выглядит примерно так:
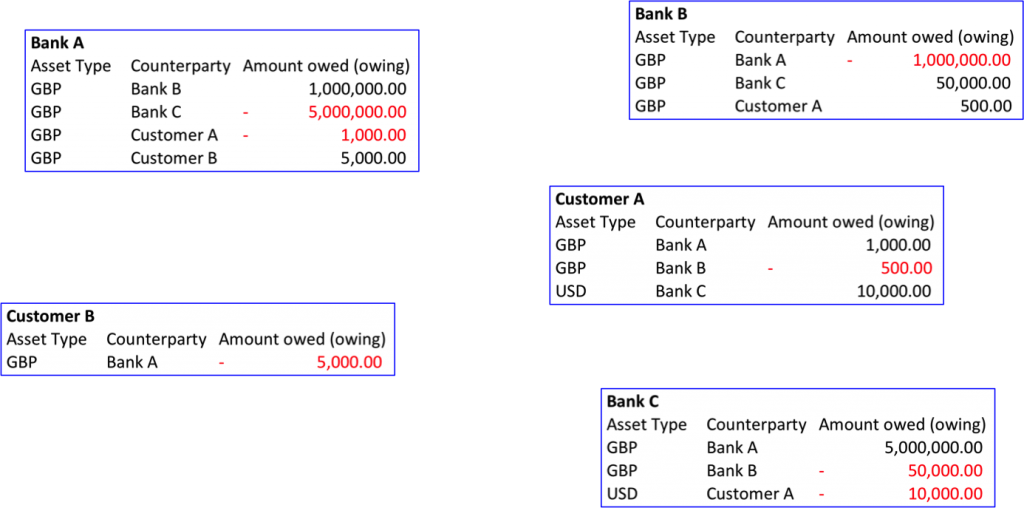
Балансы в трёх банках для двух клиентов
Сразу же можно сделать два вывода:
Во-первых, посмотрите на банки А и В. Система банка А регистрирует, что имеет миллион фунтов банка В, но и система банка В также регистрирует этот факт в другой форме — банк В должен банку А миллион фунтов. Таким образом, одна и та же информация регистрируется дважды двумя независимо разработанными, обслуживаемыми и управляемыми системами. В других областях такое дублирование оказывается гораздо более масштабным и дорогостоящим.
Во-вторых, посмотрите на клиента А. Он ссудил деньги банкам А и С, и при этом имеет овердрафт в банке В — иными словами, банки А и С должны деньги клиенту А. Кто это регистрирует? Банки А и С. Мы воспринимаем это как должное, но на самом деле весьма странно, что клиент А должен доверять сразу двум системам в смысле их точности и надёжности. Это приводит к конфликту интересов.
Отсюда возникает весьма интересный феномен — вкладчики должны доверять своим банкам, и при этом верно отчитываться по своим средствам. А сами банки должны тратить много времени и денег на разработку систем, которые делают, в общем-то, то же самое, а потом тратить ещё больше времени и денег, сверяясь друг с другом на предмет отсутствия разногласий между данными независимых систем. Даже в этом простом примере есть как минимум 7 потенциальных совпадений, нуждающихся в подтверждении.
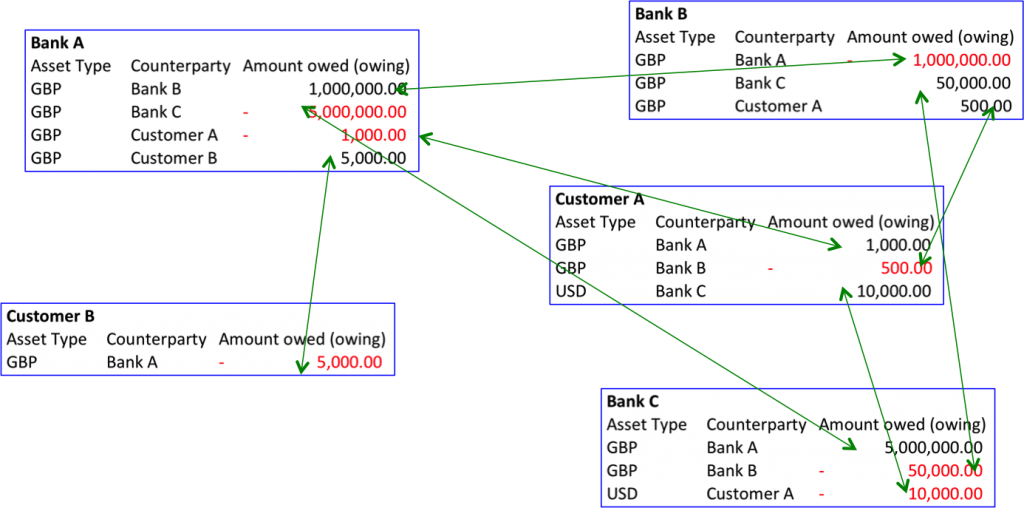
Банковские «факты» обыкновенно регистрируются двумя разными учреждениям, и поэтому требуется дорогостоящий процесс сверки данных.
На рынках ценных бумаг и деривативов действуют те же схемы
Всё, о чём говорилось раньше, касалось банковских счетов — но те же самые правила работают о системах ценных бумаг и деривативов. В последнем случае всё может быть даже хуже: нам не только нужна уверенность в том, что все признают, кто и с кем провёл какую сделку, но также нужно быть уверенными в том, что их системы не противоречат друг другу в части конечных обязательств, возникающих по сделке — они также должны работать в рамках одной и той же бизнес-логики. Подумайте, сколько практически одинаковых систем существует в мире финансов, и работа каждой лишь немного отличается от работы другой. Это зачастую приводит к тому, что данные слегка отличаются, и заканчивается всё расследованиями и урегулированиями, что весьма и весьма недёшево.
Снова к банкам
Но вернёмся к примеру с банками. С пятью реестрами, которые описывались выше, можно сделать кое-что любопытное: их можно написать по-разному, но всю информацию хранить в единственной таблице, а не распределять её по пяти разным:
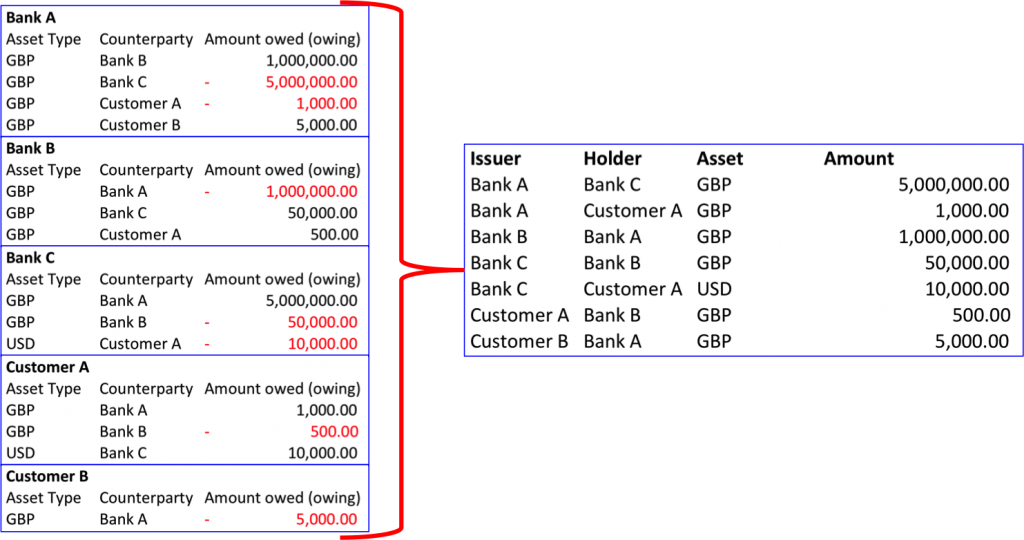
Пять отдельных реестров (слева) можно переписать с абсолютным сохранением информации, но в одной-единственной таблице (справа), и наоборот. Из одной всегда можно вывести другую. Единственная разница — таблица справа имеет лишнюю колонку, и туда можно вписать как эмитента так и держателя.
Иными словами, вместо того, чтобы пользоваться частичным взглядом каждого отдельного банка, можно создать единую таблицу, в которой записывается всё, и тем самым достичь аналогичного результата.
Почему бы не завести единый мировой банковский реестр?
Всё это поднимает интересный вопрос: если иметь свою собственную систему, которая весьма узко отображает реальность, так дорого и сложно, и при этом ещё необходимо постоянно сверяться с другими системами по пересекающимся данным — почему бы просто не платить кому-то за управление единым реестром, который все признают истинным? В конце концов, как было показано выше, любой банк по желанию может вывести собственную позицию из мега-таблицы. Конечно, необходимо продумать, как регулировать доступ к реестру — кто может его просматривать или обновлять некоторые записи, но это не является неразрешимой проблемой.
Велико искушение сказать, что всё это чистое безумие — только вдумайтесь, сколько власти окажется в руках того, кто управляет такой системой, и какие катастрофические последствия может вызвать отключение этой системы. Возможно, дорогостоящая, подверженная ошибкам, но глубоко децентрализованная система, которая существует сейчас — это та цена, которую стоит заплатить, чтобы подобного не случилось. Но это приводит к другому интересному вопросу: а что если можно получить преимущества глобальной системы, но при этом без необходимости разрешать сложные политические вопросы контроля и назначения всемогущего оператора, или ликвидировать риск отключения? Это вполне возможно.
Реплицируемый распределённый реестр
Как же можно этого добиться?
Во-первых, можно сделать много копий реестра, возможно, по одной каждому банку. Это ликвидирует риск общего краха в случае непредвиденных обстоятельств. Беспокоиться в этом случае стоит о том, как синхронизировать все эти копии — так что это не такая уж однозначная победа. Однако, копии в каждом банке могут упростить интеграцию новой системы в существующую инфраструктуру и облегчить её принятие.
Во-вторых, можно наделить участников системы — сами банки, а также их клиентов — коллективной ответственностью за обслуживание и безопасность реестра. В этом случае смухлевать окажется невозможным, так как в случае чего имя виновного станет тут же известно. Таким образом можно заменить единую всемогущую организацию моделью, где каждый вносит свой вклад в общую безопасность.
В этом случае такая новая система будет выглядеть примерно так:
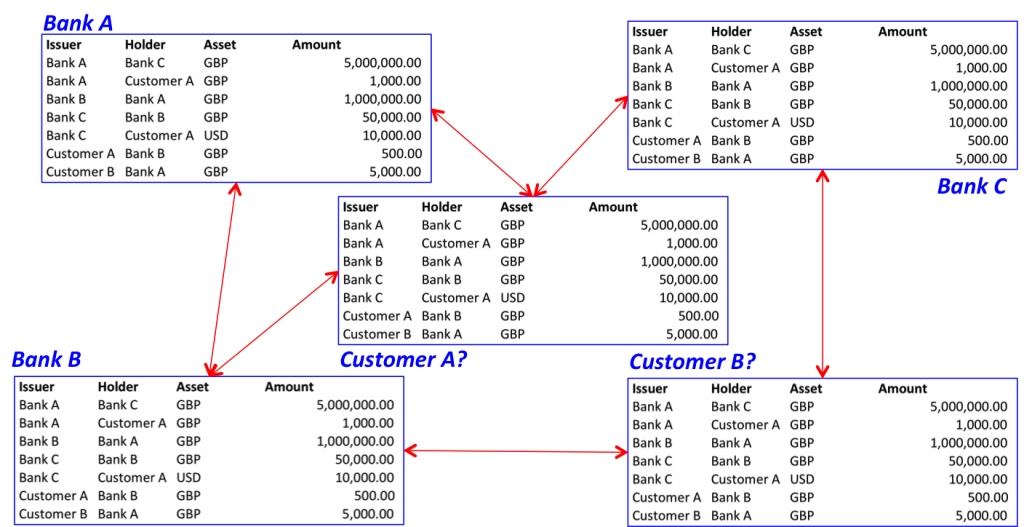
На первый взгляд эта картина выглядит похожей на ту, что была дана в начале — но у них есть качественное различие. В этой модели у всех участников есть копия реестра, но право вносить изменения есть только у тех, кого эти изменения касаются — таким образом, реестр становится как реплицированным, так и распределённым. Эту концепцию так и называют — «реплицированный распределённый реестр», и в данный момент несколько стартапов уже занимаются его разработкой.
Умные контракты
Особое внимание стоит уделить бизнес-логике этой концепции — записываемая информация, по сути, является самим соглашением между сторонами, а не отметкой о том, кто кому и сколько должен. Это открывает возможность создания «смарт-контрактов» — стороны сделки по деривативам соглашаются, что общий кусок кода соответствует соглашению, которое они заключили, и он исполняется на распределённом и реплицированном реестре, что, вероятно, полностью устраняет необходимость создавать, обслуживать, управлять и сверять собственные платформы деривативов. Коду можно даже поручить средства по реестру для автоматического управления потоками денег.
Нерешённые вопросы
Следует, однако, подчеркнуть, что нерешёнными остаются многие технические вопросы: всё это нельзя назвать однозначно хорошей идей. Так, откуда нам знать, что технология копирования работает так, как описано — особенно при всех возможных сценариях угроз? Как можно быть уверенными, что один банк (или клиент) не может видеть или даже вносить правки в информацию другого? Сколько данных будет содержать такая система? Она масштабируемая? Действительно ли правильно оформлять юридически обязывающие соглашения на программном языке, а не на человеческом?
Выводы
Имеется множество примеров систем с дорогостоящим дублированием в самых разных областях банковского дела. Идея распределённого реестра имеет потенциал, если реплицирование его для участников используется как механизм снижения рисков и обеспечение взаимности процессов. Однако, то, как всё это может воплощаться на практике, необходимо проверять — поэтому в ближайшие месяцы и годы следует провести множество экспериментов с банками и другими заинтересованными сторонами.
Примечание автора: Во избежание недопонимания этой статьи следует уточнить, что речь в ней шла не о биткоине, а о том, что можно назвать «небиткоиновым миром».
Рассылки ForkLog: держите руку на пульсе биткоин-индустрии!