






«Я сдаюсь». Нейросети не справились с воскресными загадками
Группа исследователей использовала еженедельную рубрику с головоломками ведущего NPR Уилла Шортца для проверки навыков «рассуждения» у моделей искусственного интеллекта.
Эксперты из нескольких американских колледжей и университетов при поддержке стартапа Cursor создали универсальный тест для ИИ-моделей, используя загадки из эпизодов Sunday Puzzle. По словам команды, исследование выявило интересные детали, включая тот факт, что чат-боты иногда «сдаются» и осознанно дают неверные ответы.
Sunday Puzzle — еженедельная радиовикторина, в которой слушателям задают вопросы на логику и синтаксис. Для решения не нужно иметь особых теоретических знаний, но требуются критическое мышление и навык рассуждения.
Один из сооавторов исследования Арджун Гуха объяснил TechCrunch преимущество метода «загадок» тем, что он не проверяет наличие эзотерических знаний, а формулировки задач затрудняют использование «механической памяти» ИИ-моделей.
«Эти пазлы трудные, поскольку очень сложно добиться осмысленного прогресса, пока вы его не решите — вот когда сразу складывается [окончательный ответ]. Это требует сочетания интуиции и процесса исключения», — пояснил он.
Однако Гуха отметил неидеальность метода — Sunday Puzzle ориентирован на англоязычную аудиторию, а сами тесты общедоступны, поэтому ИИ способен «жульничать». Исследователи намерены расширять бенчмарк новыми загадками, сейчас он состоит примерно из 600 задач.
В проведенных тестах o1 и DeepSeek R1 значительно превзошли другие модели в способности «рассуждать». Лидирующие нейросети тщательно проверяли себя перед ответом, но процесс занимал у них гораздо больше времени, чем обычно.


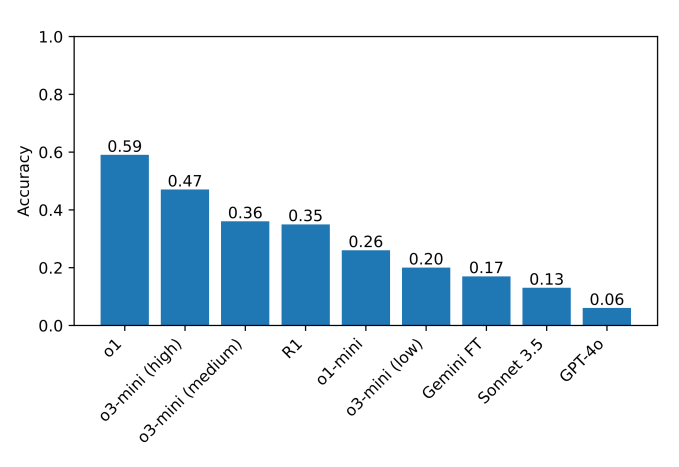
Однако точность ИИ не превышает 60%. Некоторые модели вовсе отказывались решать загадки. Когда нейросеть от DeepSeek не могла найти правильный ответ, то в ходе рассуждения писала: «Я сдаюсь», а затем выдавала неверный ответ, как будто выбранный наугад.
Другие модели по несколько раз пытались исправить предыдущие ошибки, но все равно терпели неудачу. ИИ навсегда «застревали в размышлениях», генерировали бессмыслицу, а иногда давали правильные ответы, однако потом отказывались от них.



«В сложных задачах R1 от DeepSeek буквально говорит, что он „разочаровался“. Забавно наблюдать, как модель имитирует то, что может сказать человек. Остается выяснить, как „разочарованность“ в рассуждениях может повлиять на качество результатов модели», — подчеркнул Гуха.
Ранее исследователь проверил семь популярных чат-ботов в шахматном турнире. Ни одна нейросеть не смогла полноценно справиться с игрой.
Рассылки ForkLog: держите руку на пульсе биткоин-индустрии!
