

Со дна навайбкодили
Гайд по запуску открытых ИИ-моделей из глубинного гитхаба
В развитии ИИ возник вектор, в котором децентрализация и открытый исходный код позволяют выйти за рамки популярных коммерческих решений. Локальные LLM позволяют работать с данными приватно, гибко настраивать систему под свои задачи и самостоятельно контролировать среду использования. При этом запуск таких моделей требует понимания базовых инструментов — от репозиториев и весов моделей до облачных сред и технических характеристик.
В новом материале ForkLog расскажем, как начать знакомство с автономными ИИ-моделями без затрат, какие ресурсы использовать новичкам и что предлагают разработчики OS-решений.
Первое знакомство
Для разработчиков открытых ИИ-моделей существует две основные платформы — GitHub и Hugging Face. Первая традиционно используется для публикации исходного кода, документации и установочных скриптов, вторая стала глобальным хабом для весов моделей, датасетов и готовых ML-решений. На Hugging Face публикуются сотни тысяч обученных нейросетей, от миниатюрных языковых моделей для смартфона, альтернативных генераторов медиаконтента до специализированных алгоритмов для ученых и энтузиастов.
Выбрать необходимую модель помогают метрики активности сообщества. На GitHub они представлены количеством звезд (stars), регулярностью обновлений (commits) и скоростью решения проблем (issues).
Отдельно важно проверять происхождение продукта и подлинность репозитория. Популярные OS-сборки регулярно становятся приманкой для кибермошенников, распространяющих вредоносный код под видом известных ИИ-инструментов.
Следующий этап знакомства с локальными ИИ-моделями — опробовать их функционал на практике. Для пользователей без мощного железа существуют бесплатные и условно-бесплатные облачные платформы.
Самое популярное решение — Google Colab — облачная среда, предоставляющая доступ к графическим процессорам (GPU) прямо из браузера. Бесплатная подписка позволяет работать на системе c ускорителем Nvidia Tesla T4 в среднем от двух до четырех часов в зависимости от нагрузки. Альтернативами выступают Kaggle Notebooks и Hugging Face Spaces. Последняя позволяет взаимодействовать с моделями через готовые веб-интерфейсы вроде Gradio или Streamlit.
Также в работе с федеративными решениями стоит учитывать юридический аспект. Многие популярные проекты доступны под классическими лицензиями, вроде MIT или Apache 2.0, что позволяет использовать их в том числе в коммерческих целях с минимальными ограничениями.
Однако существуют и специфические подходы. Meta распространяет свои флагманские модели под собственной лицензией Llama 3.1 Community License, которая требует получения специального разрешения, если ежемесячная аудитория сервиса превышает 700 млн пользователей.
Строгие копилефт-лицензии вроде GNU General Public License также встречаются, обязывая открывать код всех производных продуктов.
Мой личный аналог ChatGPT
Из огромного числа автономных LLM общего назначения (аналогов ChatGPT или Gemini) выбрать необходимую модель помогают независимые рейтинги на основе слепого тестирования и метрик производительности вроде Open LLM Leaderboard и Chatbot Arena.
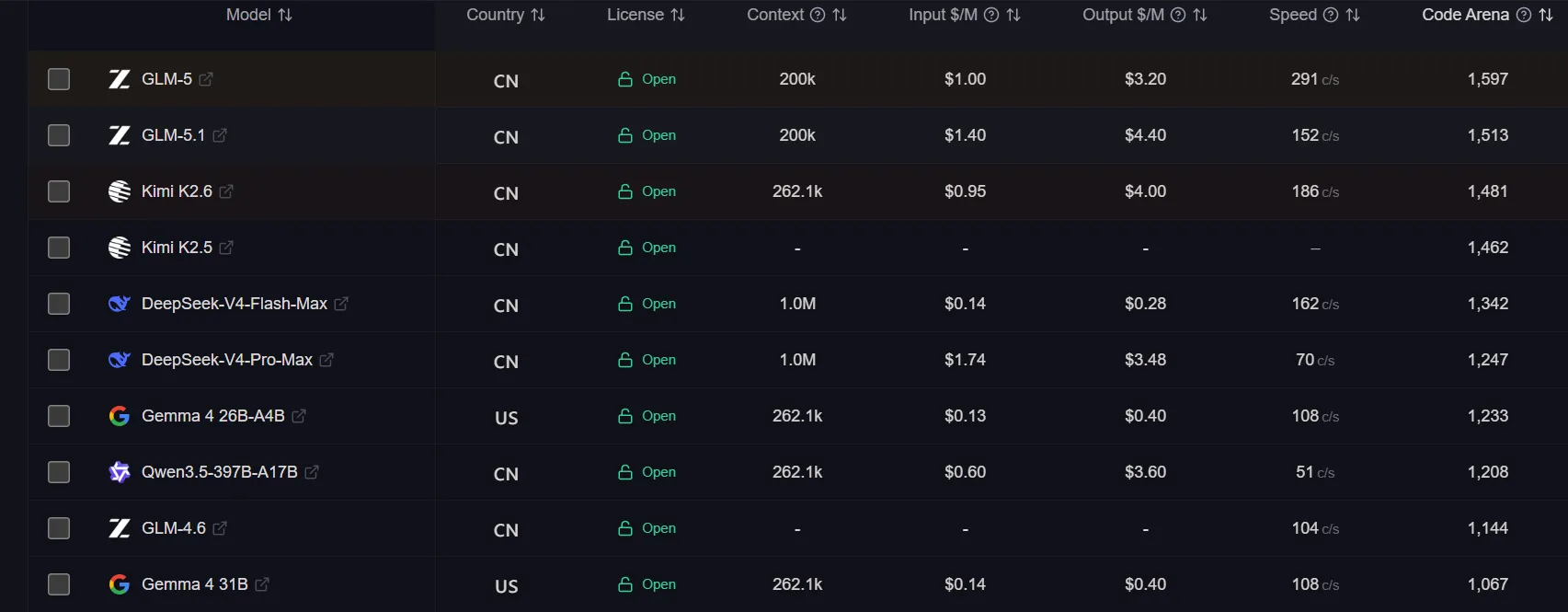
Золотым стандартом сегмента считается семейство моделей Llama разработчика Meta и Qwen от Alibaba. Эти модели хорошо работают с длинным контекстом, справляются с многошаговыми запросами и подходят для задач вайбкодинга и программирования. Благодаря открытому фреймворку Ollama их установка сводится к одной команде.
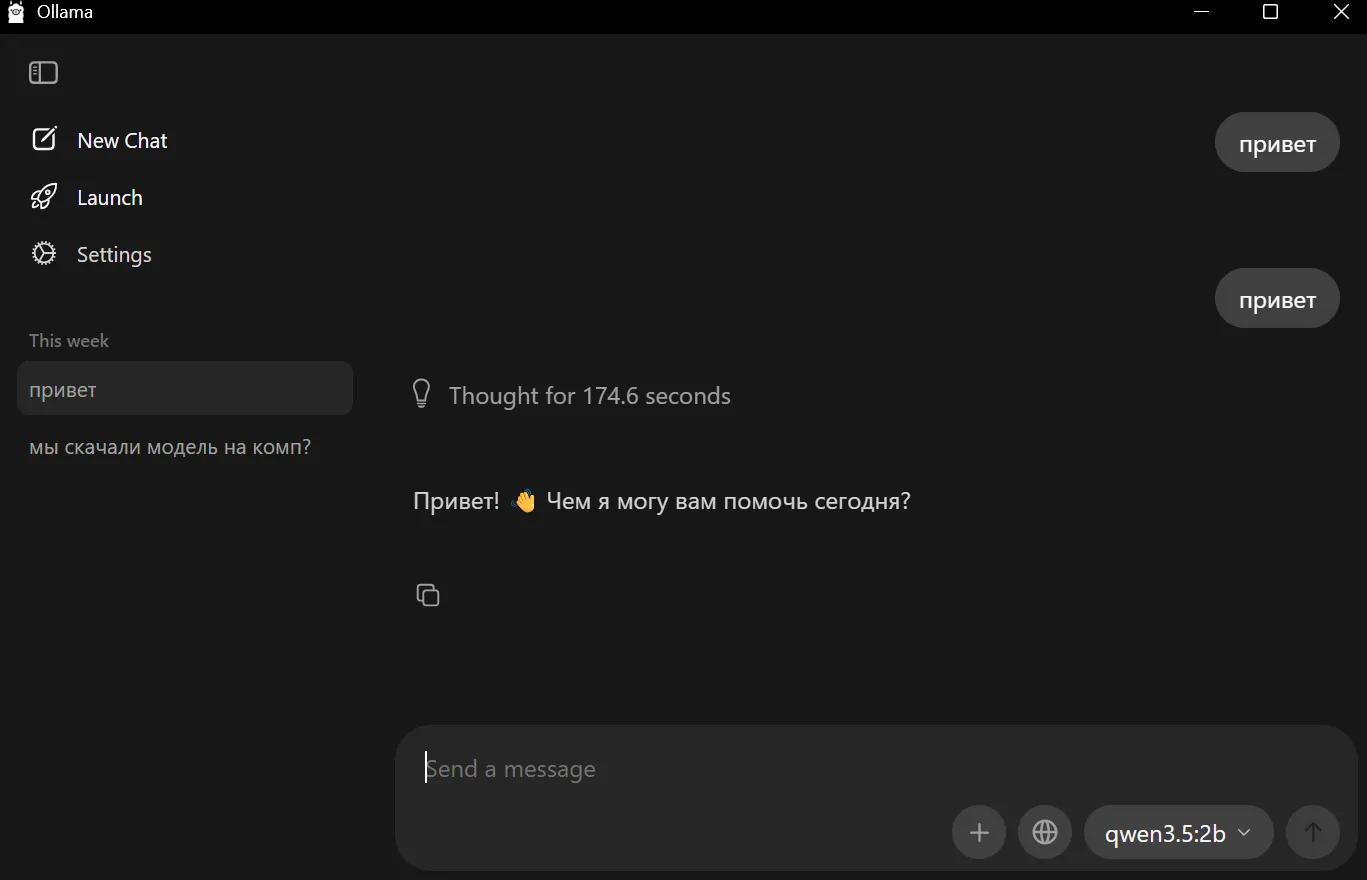
Во время теста, проведенного для написания данного материала, модель qwen3.5:2b удалось запустить на ноутбуке без дискретной видеокарты на базе Core i7 с 8 ГБ RAM и SSD, закрыв при этом тяжелые приложения: мессенджеры и браузеры.
«2b» означает 2 млрд параметров. Чем выше значение, тем более сложные связи может уловить нейросеть. Например, модель 2b выучит базовую грамматику и простые команды, тогда как 122b запомнит факты из квантовой физики, тонкости юридических документов и научится планировать задачи на десять шагов вперед.
Каждый параметр занимает физическое место на жестком диске и, самое главное, в оперативной памяти. 2b использовала около 4-5 ГБ RAM и стала максимальной для запуска на такой машине. При этом ответ на простейший запрос «привет!» модель генерировала почти три минуты.
Ориентировочная градация моделей:
- 0.5b-2b. Быстрые, могут работать на старых ноутбуках и смартфонах. Идеальны для простых задач (маршрутизация команд, базовое саммари, автодополнение коротких строк кода). Склонны к галлюцинациям на сложных запросах;
- 3b-4b. Баланс скорости и качества. Хороши для мобильных устройств, умного дома и задач автоматизации. Например, чат-бот можно попросить убавить свет в комнате, включить кондиционер или поднять шлагбаум;
- 7b-9b. Требуют около 6–8 ГБ свободной оперативной памяти. Мощные модели с пониманием контекста и глубокой логикой, подходят для программирования и работы с большими текстами.
В своем недавнем исследовании вайбкодинга в Web3 Владимир Слипер выяснил, что на машину уровня MacBook Air 16 ГБ RAM подойдут qwen2.5-coder:7b, qwen3:8b, llama3.2:3b, deepseek-r1:8b. Модели помощнее требуют инвестиций в мощный ПК с хай-энд видеокартами либо установки на арендуемых серверах.
Приватная обработка данных, 3D-печать и защита пользователя
Варианты взаимодействия с открытыми ИИ-моделями зависят от уровня подготовки пользователя и аппаратного обеспечения. Существуют проекты, упакованные в удобные инсталляторы (файлы с расширением .EXE) или мобильные приложения, работающие «из коробки». Другие представляют собой заброшенные GitHub-репозитории, где установка превращается в многочасовую борьбу с конфликтами устаревших библиотек.
Прикладные ИИ-модели сегодня используются далеко не только для генерации текста. Даже поверхностный анализ экосистемы позволяет выделить десятки специализированных инструментов под конкретные задачи.
Работа с видео и 3D:
- CogVideoX. Открытая модель от Zhipu AI для генерации видео по текстовому описанию. Позволяет создавать реалистичные короткие ролики, обладает открытыми весами и может быть развернута в средах вроде Jupyter или Colab при наличии достаточного объема видеопамяти;
- DepthCrafter. Инструмент для извлечения информации о глубине резкости из видео. Полезен для специалистов по VFX и 3D-моделированию. Он позволяет создавать карты глубины высокой точности для каждого кадра динамичной сцены;
- TRELLIS (Morfx 3D). Передовая система генерации 3D-ассетов. Проект позволяет создавать высококачественные трехмерные модели из изображений или текстовых запросов, оптимизируя их для использования в игровых движках.
Звук и распознавание:
- CosyVoice. Мультиязычная модель синтеза речи с поддержкой клонирования голоса. Позволяет генерировать реалистичный аудиоряд, сохраняя интонации и эмоциональную окраску исходного спикера;
- Whisper-WebGPU. Имплементация модели распознавания речи от OpenAI, переписанная для работы непосредственно в браузере с использованием API WebGPU. Это означает, что расшифровка аудио происходит локально, обеспечивая полную приватность без передачи аудиофайлов на сторонние серверы;
- BirdNET-Analyzer. Нейросеть от Корнеллского университета для определения видов птиц по их пению. В отличие от популярного приложения Merlin Bird ID, которое в значительной степени полагается на облачную обработку для некоторых функций, BirdNET-Analyzer предоставляет полный контроль над процессом анализа локально и может использоваться для массовой обработки гигабайтов полевых записей.
Программирование и защита пользователя:
- Screenshot-to-Code. Утилита для перевода скриншота веб-страницы или мобильного приложения в чистый HTML-, Tailwind- или React-код. Хотя часто проект работает в связке с платными API (Claude, GPT-4), архитектура позволяет подключать открытые мультимодальные модели;
- MinerU/Magic-PDF. Проект для точного извлечения структурированных данных из PDF-документов. Модель распознает текст, математические формулы и таблицы, преобразуя сложную верстку в формат Markdown;
- Fawkes. Вносит невидимые глазу изменения в изображения, мешая системам распознавания лиц идентифицировать человека. Загружается локально на ПК через файл с расширением .EXE и может использоваться для аватаров в соцсетях;
- Nightshade. «Отравляет» пиксели картинки для запутывания алгоритмов обучения ИИ-компаний, если они это делают без разрешения. Например, на запрос «собака» модель сгенерирует изображение кошки.


Борьба с библиотеками и первый успех
После установки ИИ-моделей с понятными UI/UX необходимо было выяснить, насколько легко удастся развернуть тяжелый репозиторий в облаке, причем бесплатно.
FLUX.1 от стартапа Black Forest Labs — одна из передовых моделей генерации изображений, конкурирующая с корпоративными Midjourney и Nano Banana. При наличии необходимого оборудования софт может работать автономно без доступа к интернету и позволяет обходить цензуру.
В тесте использовалась самая легкая бесплатная версия FLUX.1 Schnell. Для удобства взаимодействия с открытыми решениями разработчики создают целевые фреймворки вроде Ollama. Для генерации изображений популярны графические интерфейсы ComfyUI и Forge.
Во время попыток установить имплементацию Forge — cagliostro-forge-colab — пришлось потратить целую сессию доступа к GPU от Google Colab. Проблема оказалась в классической ошибке новичка — несоответствии версий Python, облачной среды и самой модели. За четыре часа вайбкодинга с помощью бесплатной версии Gemini 3 Flash успеха добиться не удалось.
В итоге пришлось отказаться от установки фреймворка и перейти непосредственно к развертыванию FLUX.1, но уже в следующую бесплатную сессию в другой день.
На практике бесплатный Google Colab удобнее использовать на выходных: в это время платформа нередко предоставляет более продолжительный доступ.
Модель заняла порядка 34 ГБ дискового пространства облачного SSD. Но все сопутствующие установке процессы в итоге использовали около 86 ГБ.
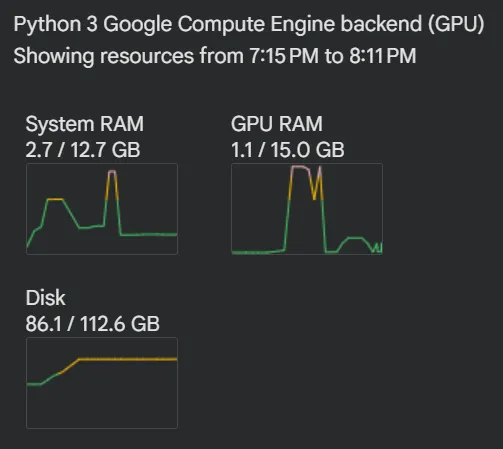
На первом этапе модели FLUX.1 Schnell не хватило видеопамяти ускорителя Nvidia Tesla T4. Неадаптированная конфигурация упиралась в лимиты GPU, пока после серии простых экспериментов с кодом Gemini 3 Flash не помогла внести правки, используя поэтапную загрузку и очистку памяти. В результате из доступных 16 ГБ видеопамяти в процессе генерации использовалось около 3 ГБ.
Процесс создания одного изображения занимал около семи минут. Учитывая, что это бесплатная версия открытой модели, результат приятно удивил.

При попытке несколько раз сгенерировать образ рок-певца Мэрилина Мэнсона в викторианском стиле с компаньоном FLUX.1 Schnell, вероятно, не распознала отсылку к конкретной персоне и воспроизвела лишь обобщенный визуальный шаблон.

Сложные и невероятные
Открытые нейросети давно используются не только для генерации текстов и изображений, но и для более узких и необычных задач. Ярким примером нестандартного применения ИИ-архитектуры стала модель GameNGen, способная воссоздавать игровой процесс классического шутера DOOM в реальном времени.
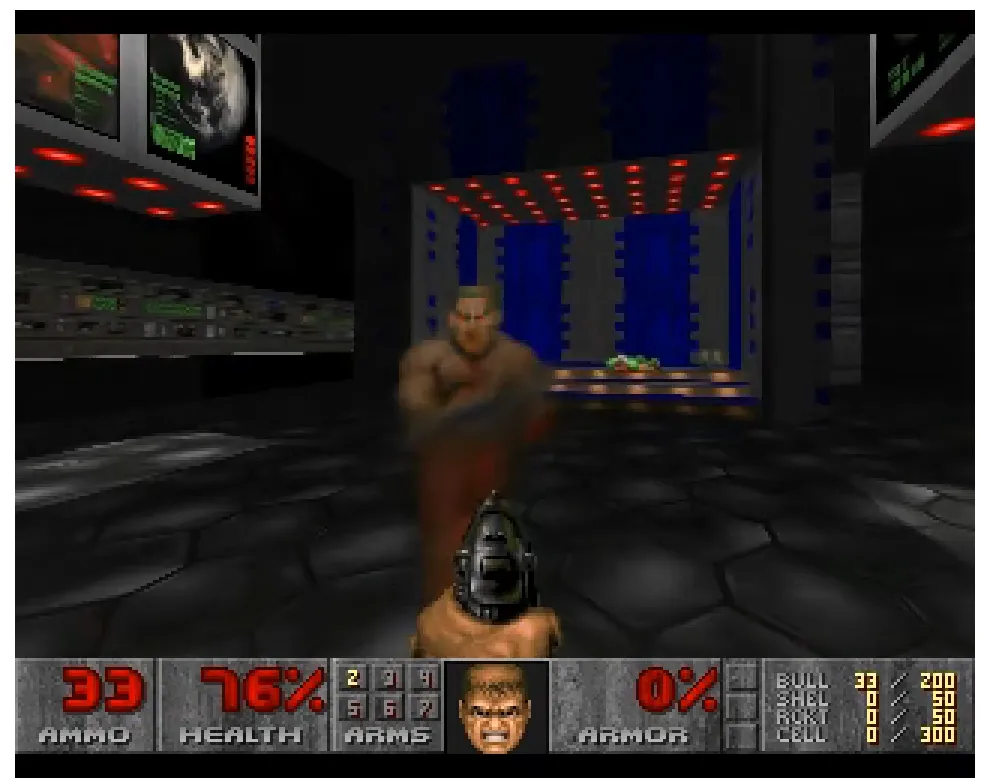
GameNGen не симулирует игру в привычном смысле, а последовательно генерирует видео: модель предсказывает, как должен выглядеть следующий кадр после действия пользователя (например, движение или выстрел). Из-за этого враги, объекты и изменения сцены не «просчитываются» движком, а визуально воспроизводятся как наиболее вероятный результат.
Среди автономных систем выделяется проект Voyager — ИИ-агент для Minecraft. Он самостоятельно исследует игровой мир, добывает ресурсы и непрерывно самообучается.
Научное сообщество также активно адаптирует открытый ИИ под свои нужды, например, используя алгоритмы для расшифровки истории. Так, исследователи из Тель-Авивского и Мюнхенского университетов обучили модель Akkademia напрямую переводить древнюю аккадскую клинопись на английский язык. Она позволяет обрабатывать тысячи поврежденных глиняных табличек, ускоряя работу археологов в десятки раз.
Не менее интересен проект MinD-Vis. Эта система анализирует данные функциональной МРТ и пытается реконструировать изображения, которые испытуемый наблюдает в момент сканирования. То есть генерирует интерпретацию увиденного человеком на основе паттернов мозговой активности.
Подобные инициативы доказывают, что искусственный интеллект превратился в универсальный инструмент познания и моделирования реальности. Переход инициативы от закрытых корпоративных API к открытому исходному коду формирует совершенно новую парадигму развития технологий. Сегодня любой исследователь, разработчик или энтузиаст имеет возможность развернуть инфраструктуру, которая еще несколько лет назад требовала многомиллионных инвестиций в серверные фермы.
Развитие экосистемы неизбежно сопровождается улучшением пользовательского опыта: на смену сложным скриптам приходят интуитивные интерфейсы и автоматизированные среды развертывания. Использование инструментов вроде Ollama и Forge демонстрирует, что приватность, отсутствие цензуры и высокая производительность могут гармонично сосуществовать в одном программном решении. Будущее ИИ-индустрии сегодня во многом зависит от того, насколько сильной, масштабируемой и независимой останется открытая экосистема.
Рассылки ForkLog: держите руку на пульсе биткоин-индустрии!